Week 3!
Network analysis
- Turn relationships into networks
- Visual representations can be confusing

- Useful when relationships are important part of understanding a process
Topic modeling
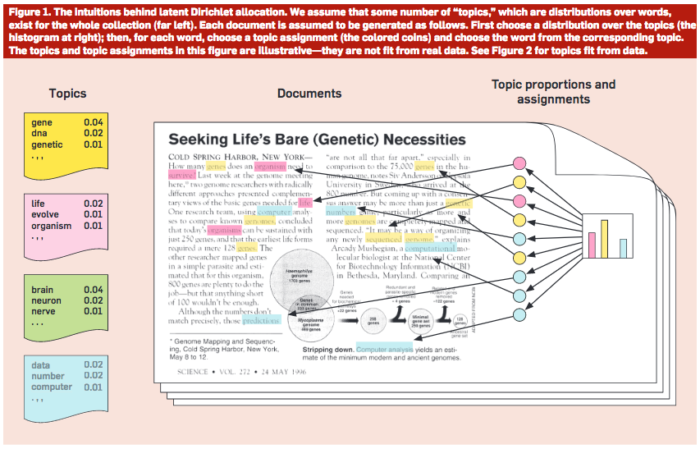
- Goal is to find a set of k topics where each topic is made up of a combination of terms and each document is made up of a combination of topics.
- Requires a lot of interpretation
- Computational grounded theory (Nelson, 2017) is one attempt to get “best of both worlds”
Comments and functions