An agent-based model of community joining

Jeremy Foote
Northwestern University

Benjamin Mako Hill
University of Washington

Nate TeBlunthuis
University of Washington
Groups size distributions vary
Universities look like this: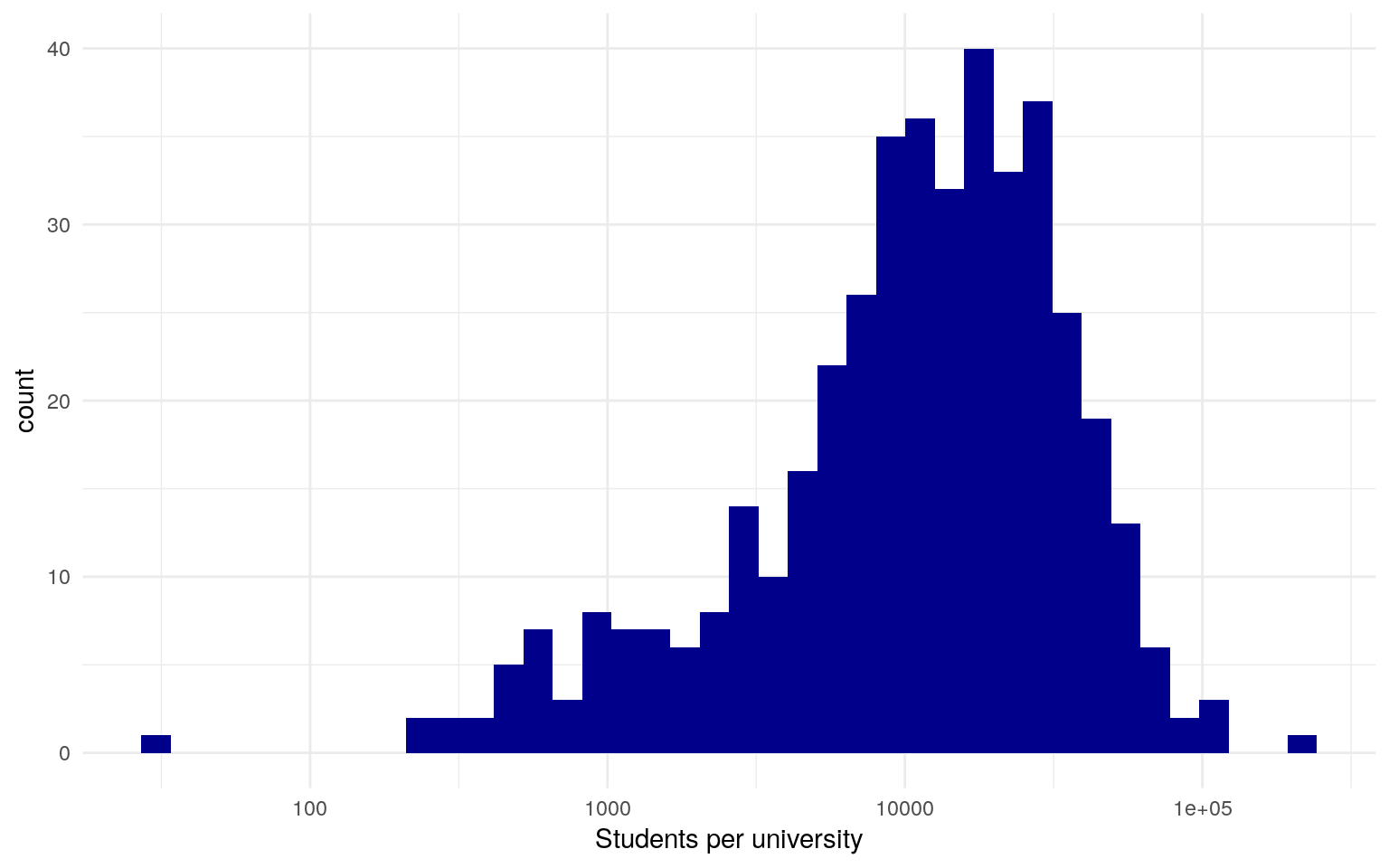
Data from Wikidata
Online groups
While reddit looks like this:
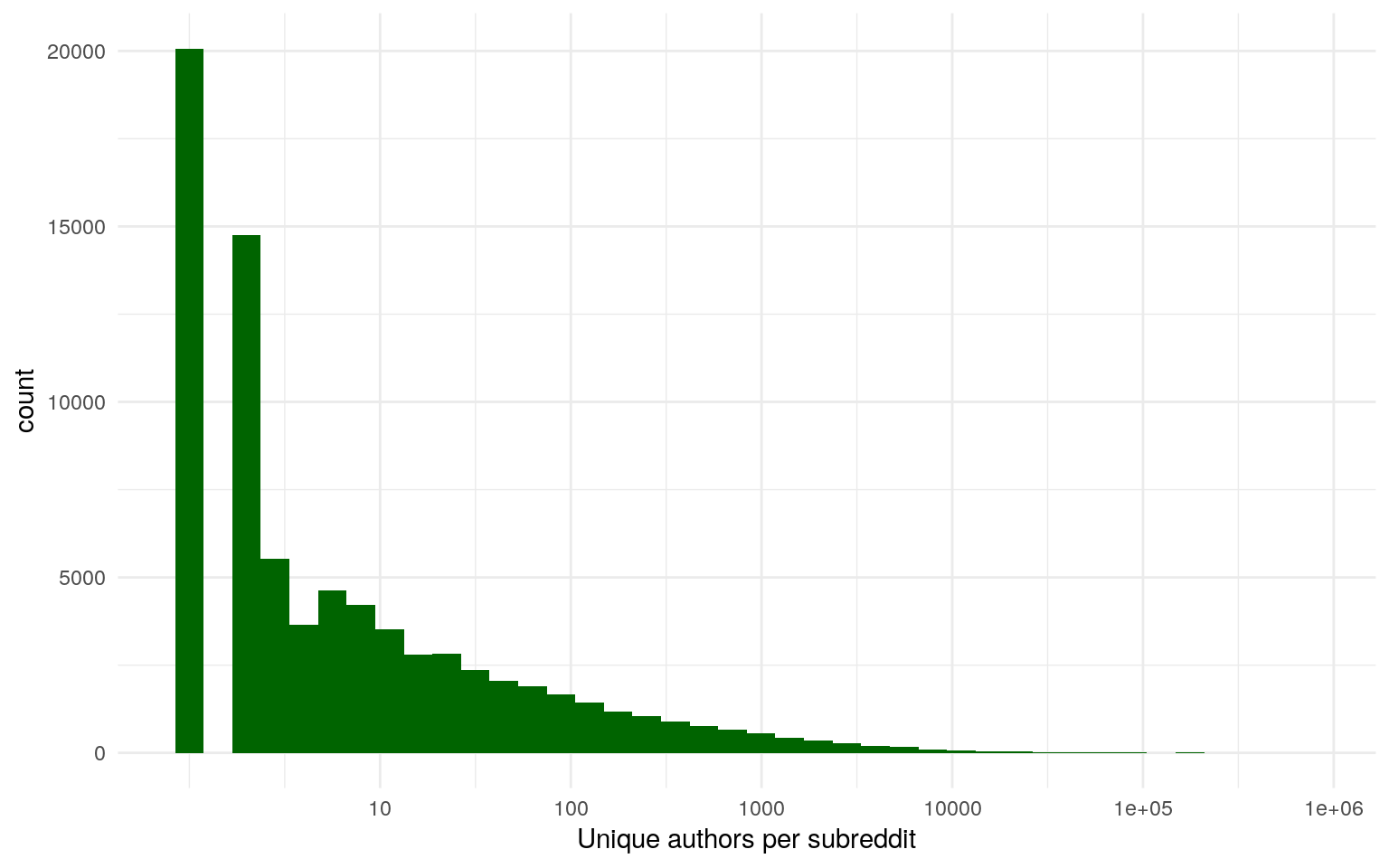
Data from Stuck_in_the_Matrix on BigQuery
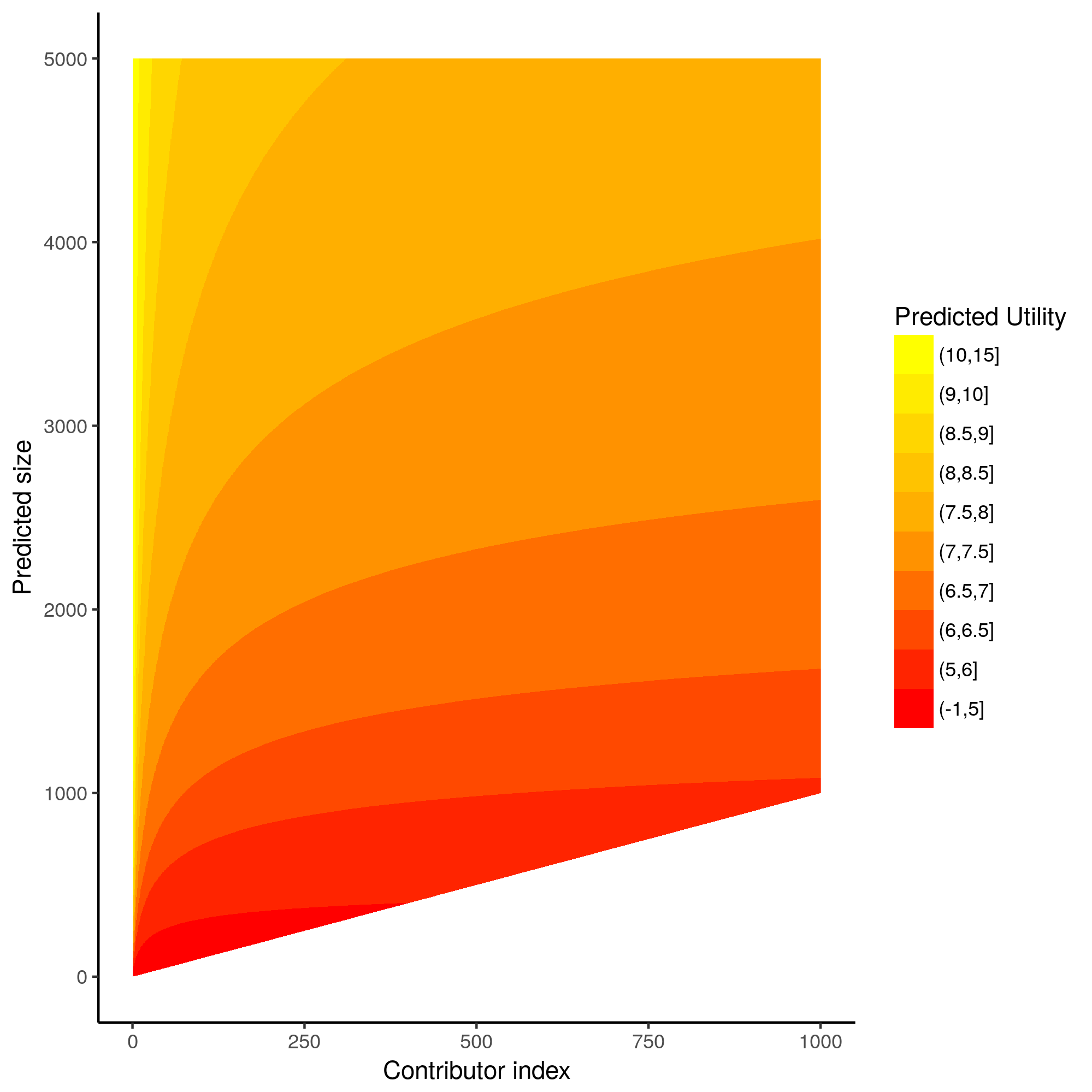
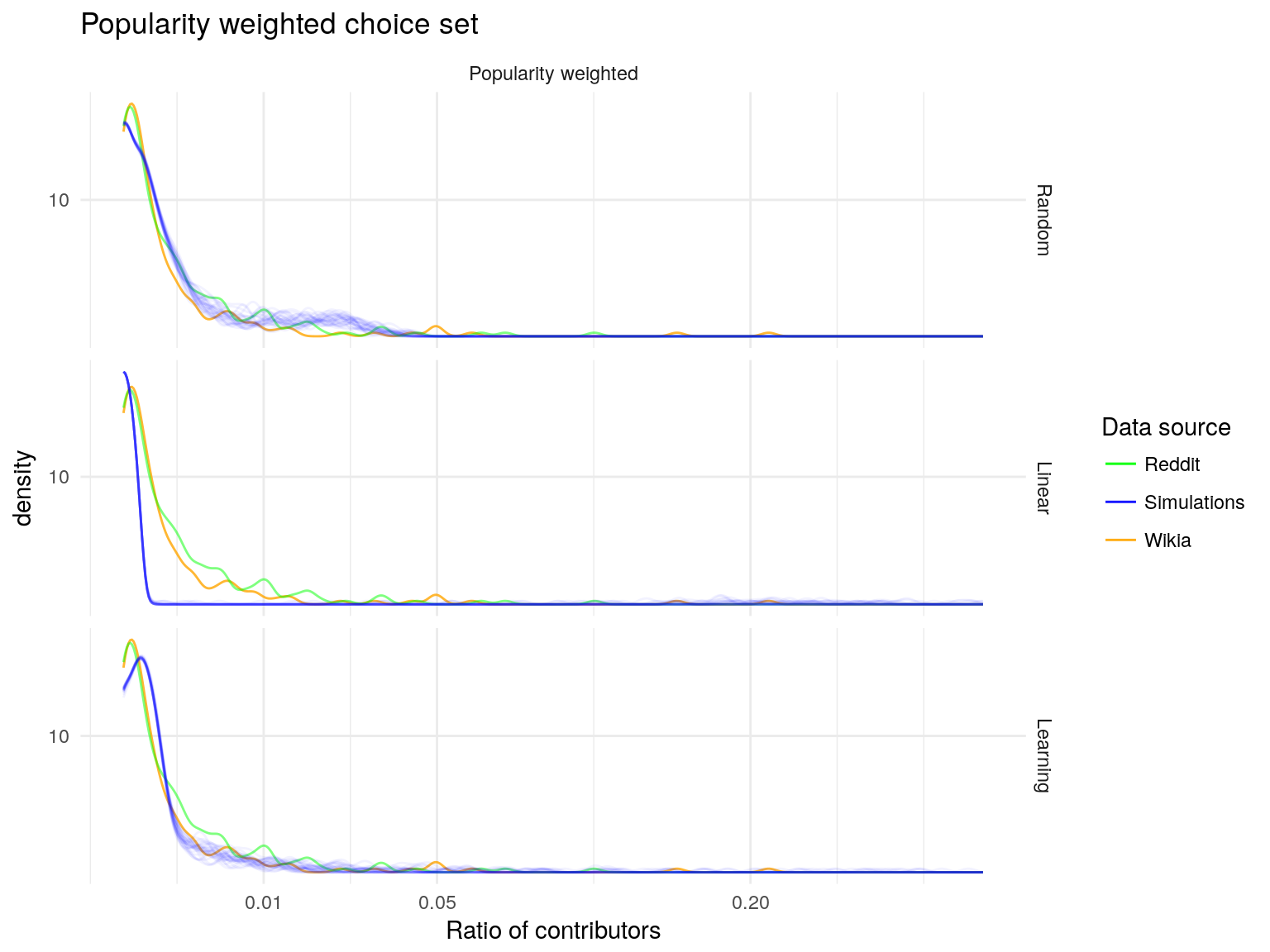
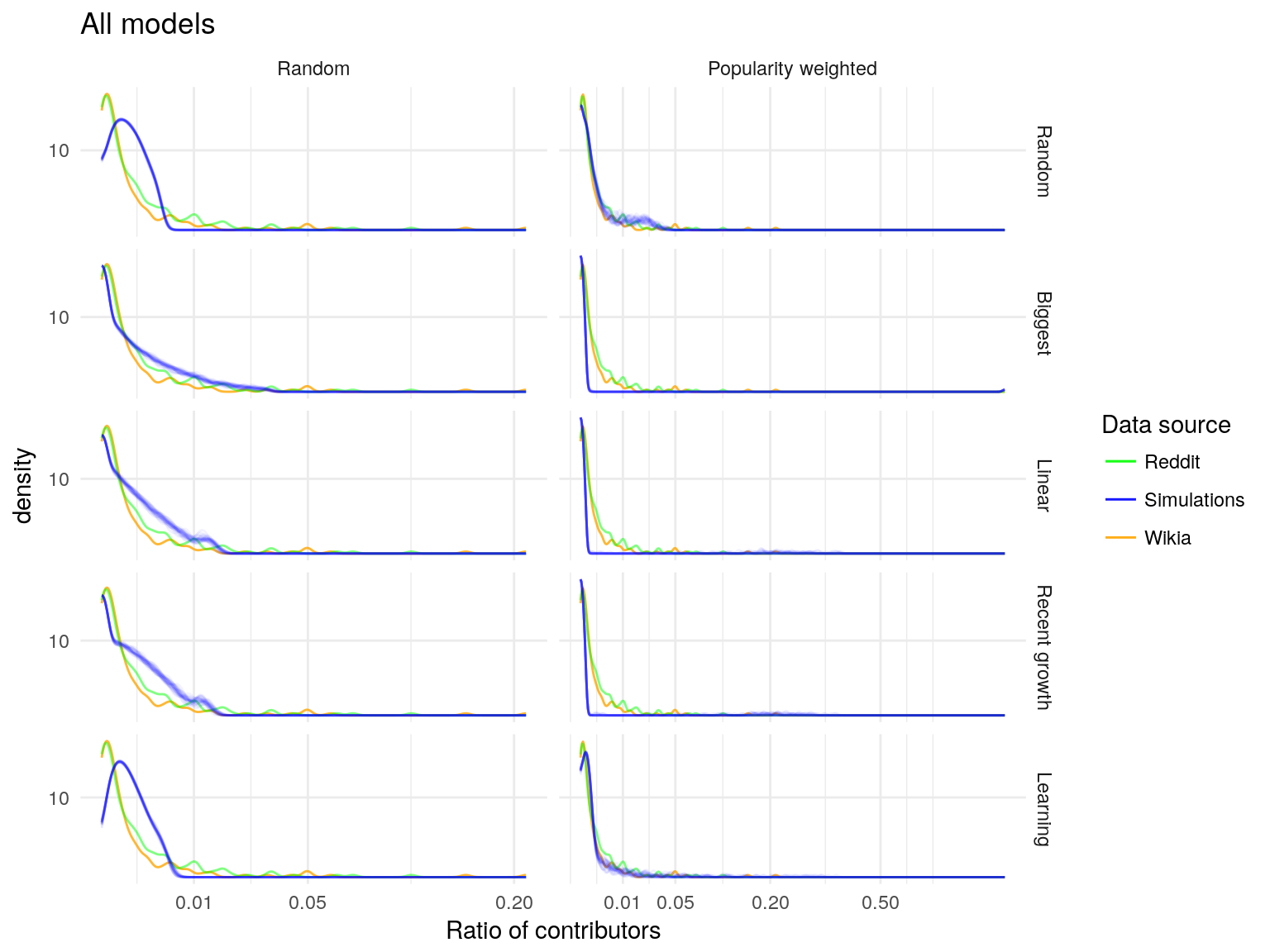
Utility
Empirical distributions
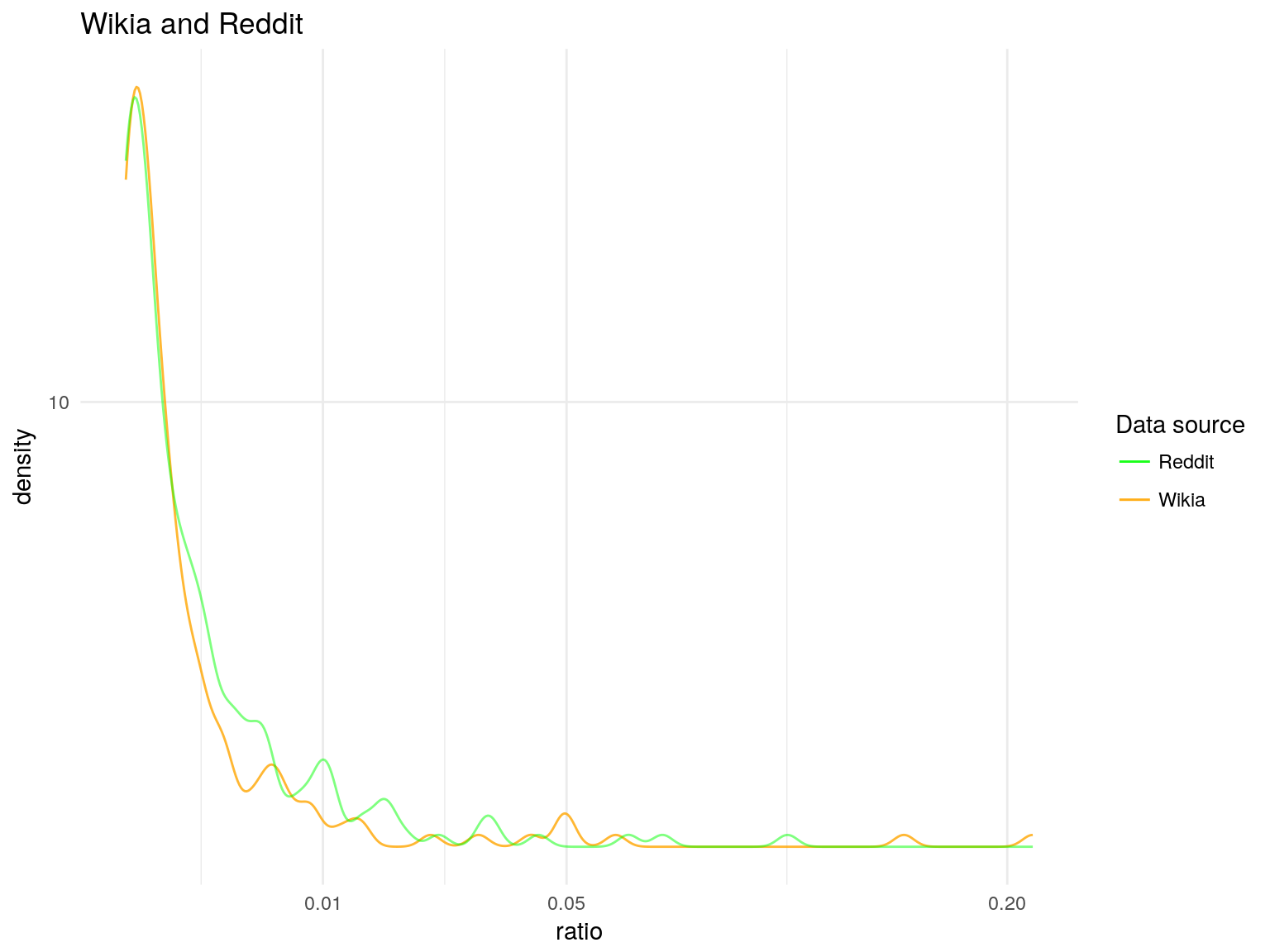
Simulated distributions
Thanks!
Jeremy Foote
@jdfoote
Benjamin Mako Hill
@makoshark
Nate TeBlunthuis
@groceryheist
All models
–> –> –> –>
–> –> –> –> –> –> –> –>
–>