The Formation and Growth of Collaborative Online Organizations

Jeremy Foote
Northwestern University / Purdue University
September 26, 2019

Examples

![]()
![]()
Most COO do not succeed
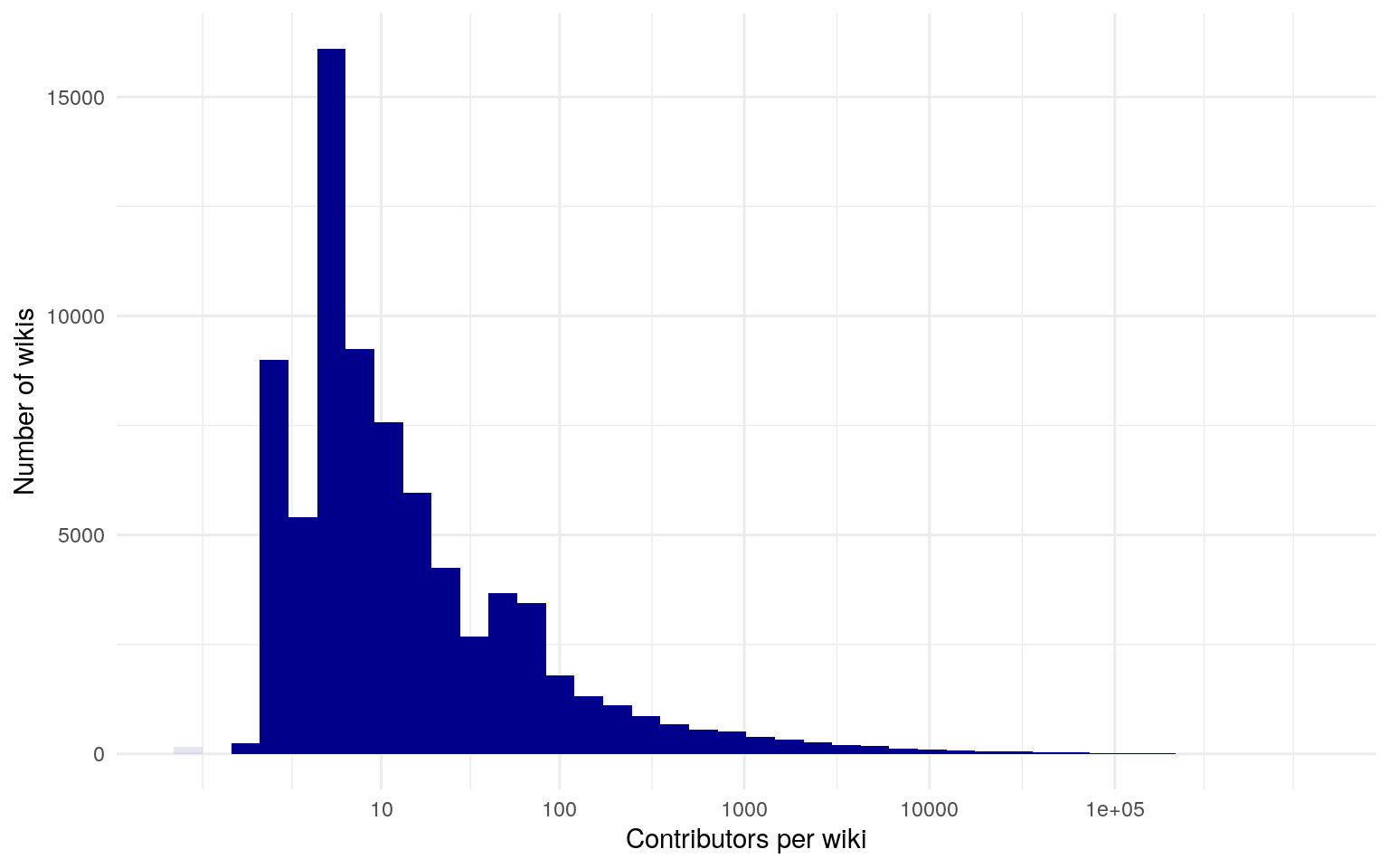
- COO size is highly skewed, with top organizations getting most of the contributions
Approach 2: Predicting COO outcomes based on membership, structure, and design



Approach 3: Online Organizational Ecology predicts outcomes based on community-level relationships



People are influenced by individual attributes, technology, and the state of the system

Edits taken from wiki talk pages on Wikia
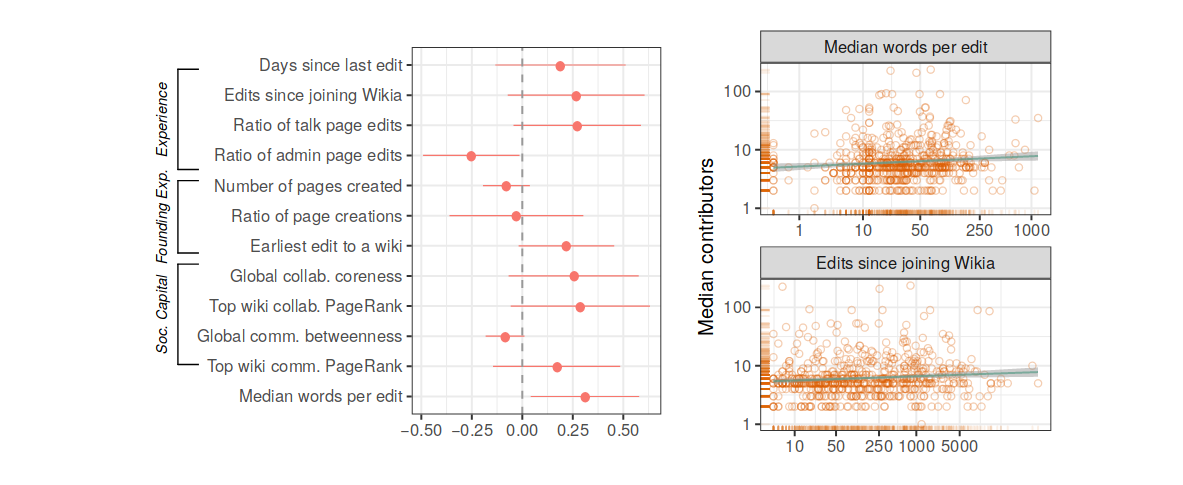
Relationships between communication structures and productivity
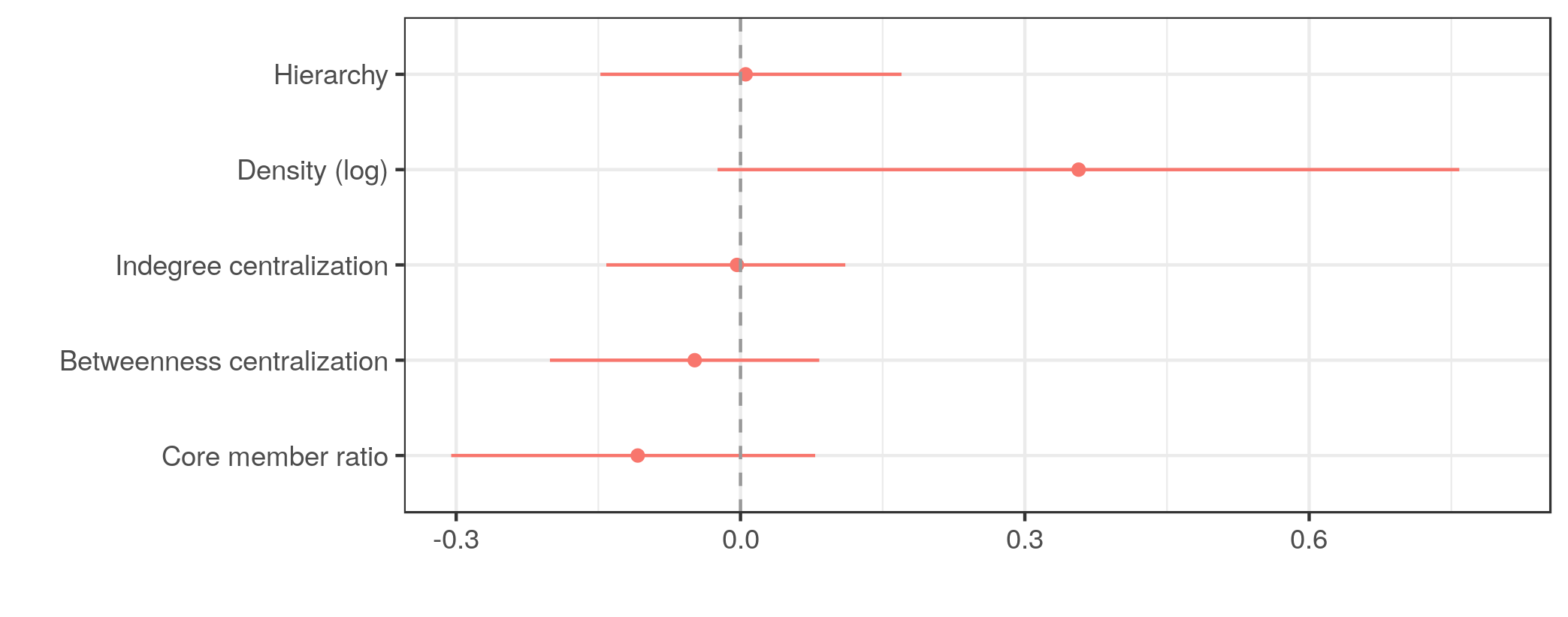
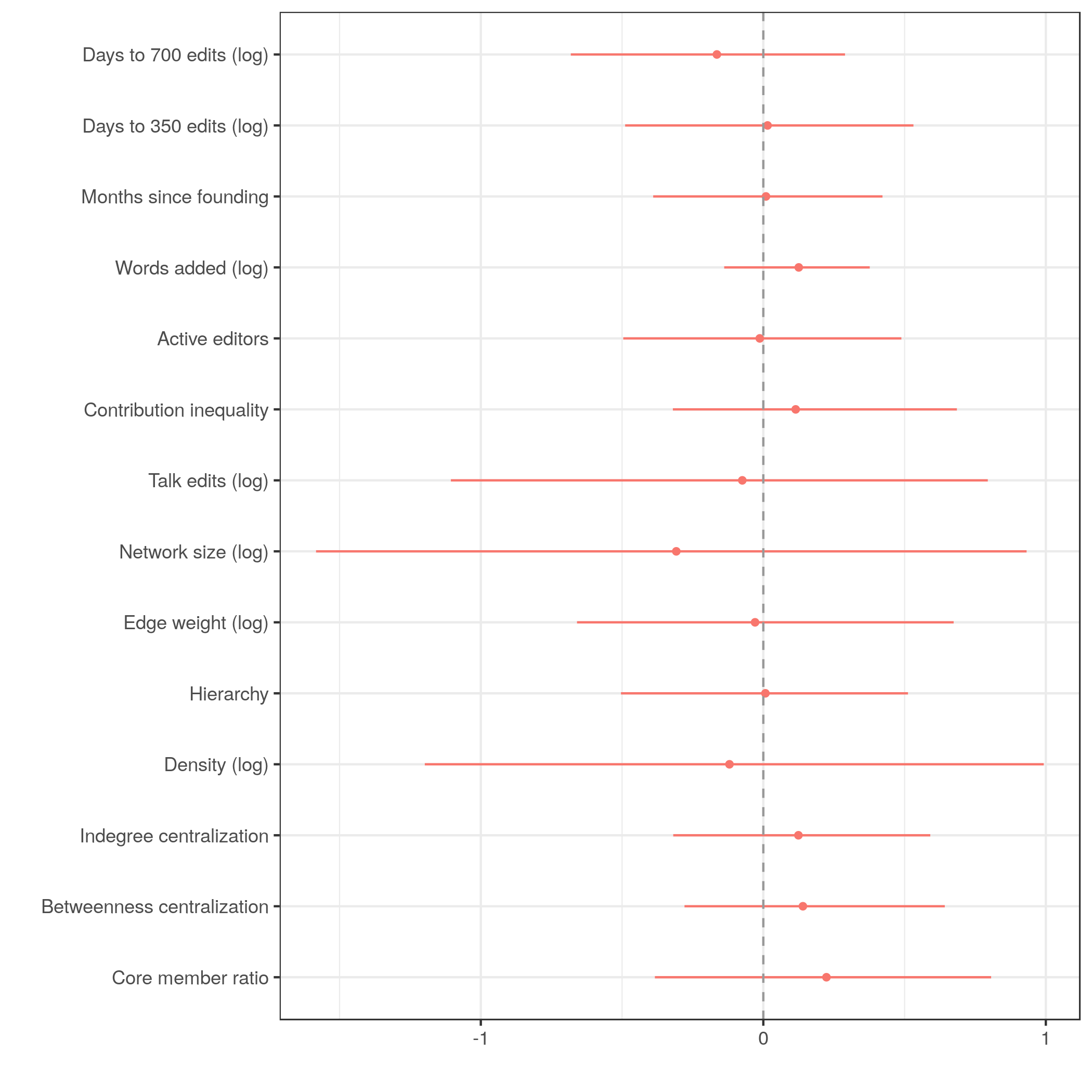
Bootstrapped 95% confidence interval for β coefficents
There is basically no relationship between communication structures and survival
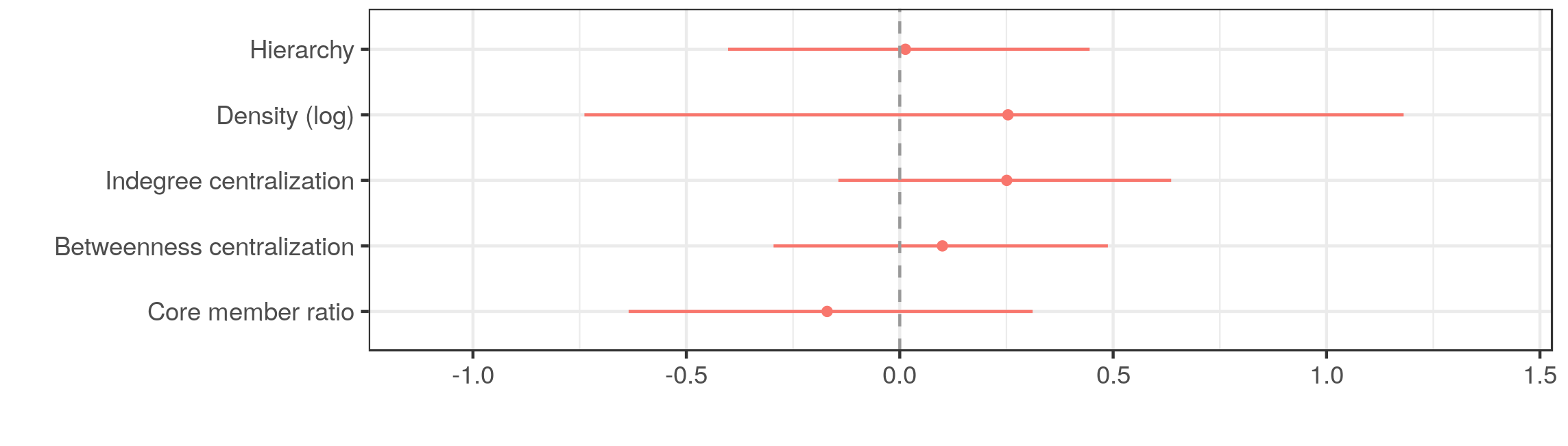
Bootstrapped 95% confidence interval for β coefficents
Why do people start new communities?

Foote, Gergle, and Shaw. (2017). Starting Online Communities: Motivations and Goals of Wiki Founders, CHI 2017
Previous research typically treats small communities as failures
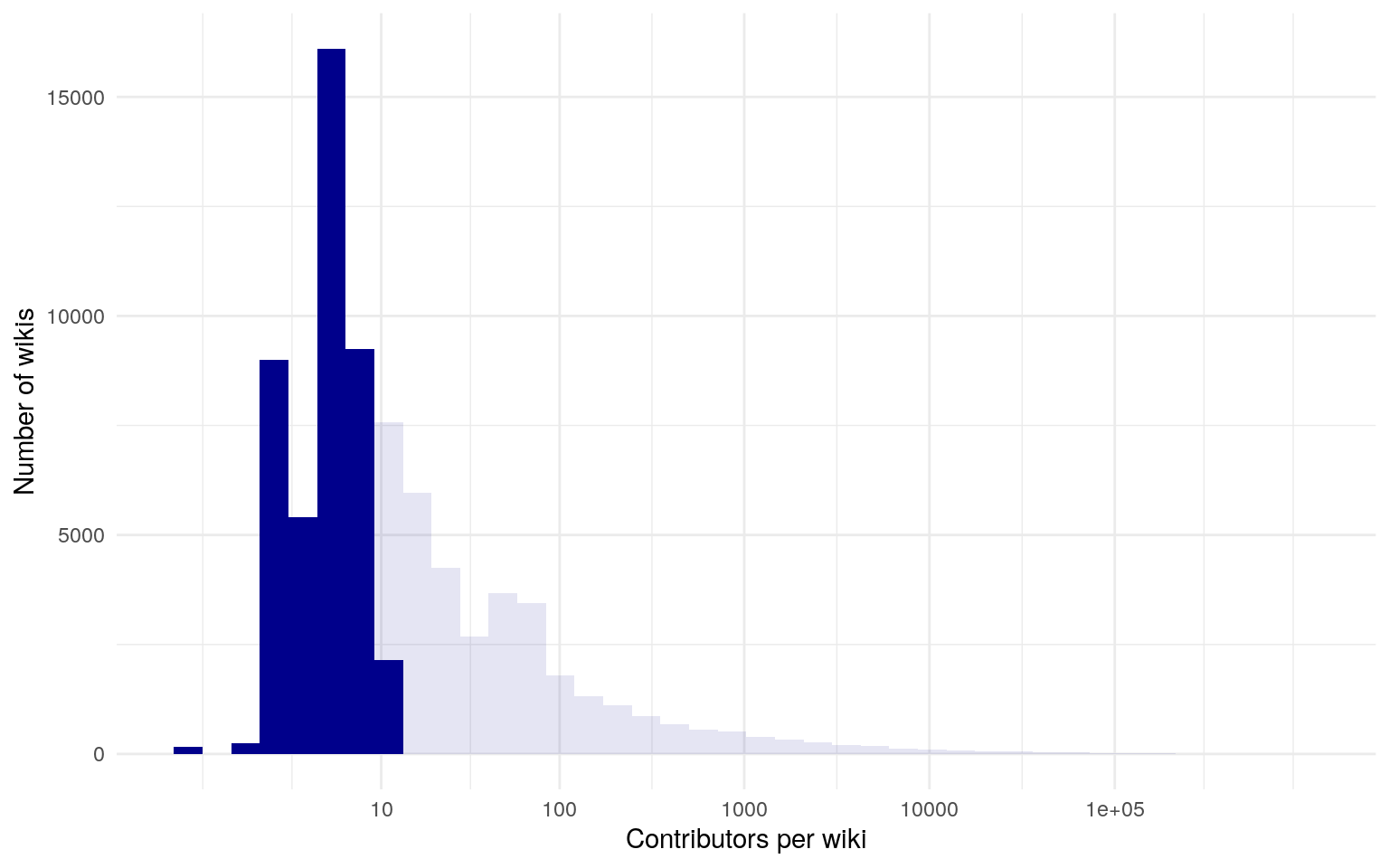
Most projects are on niche topics for small communities
Projected contributors after 30 days
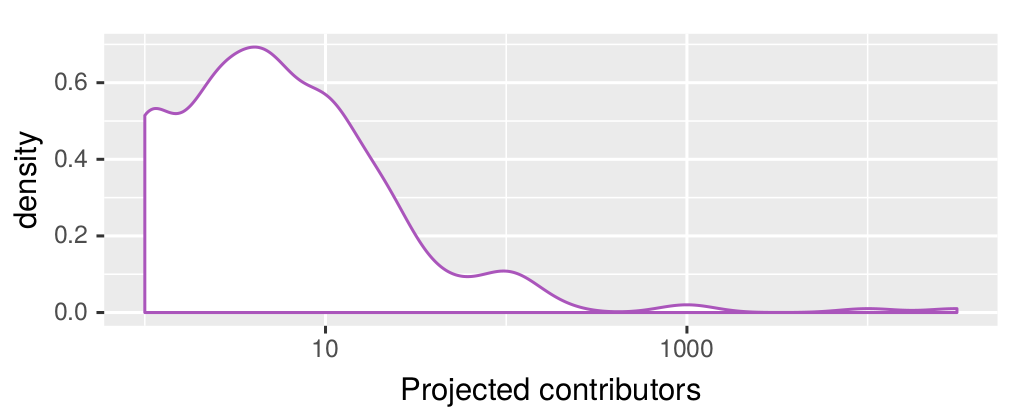
Who starts new communities?

Foote and Contractor. (2018). The behavior and network position of peer production founders. Lecture Notes in Computer Science.
We examined the behavior and network position of ~61,000 wiki editors
 Timeline of data collection
Timeline of data collection
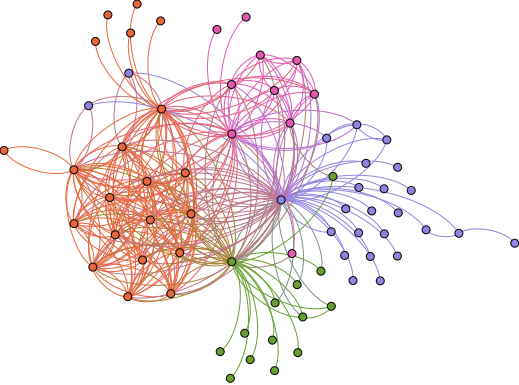 Network graph of the Spongebob wiki from Wikia
Network graph of the Spongebob wiki from Wikia
Non-newbie founders are more active with more diverse experience, but at the periphery of social networks
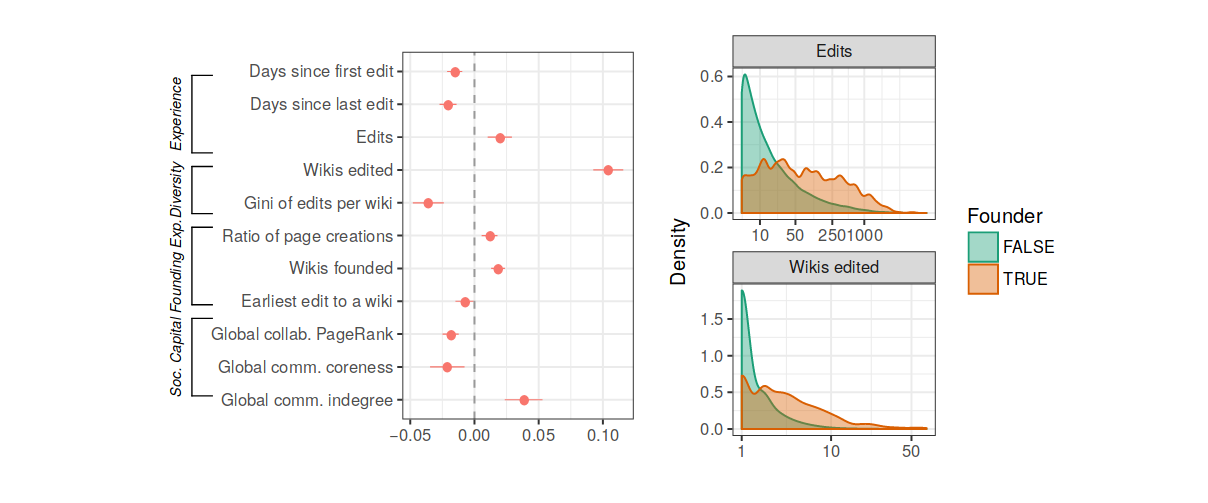
Overall, past behavior and networks have little relationship with community growth
Online group sizes have heavy-tailed distributions
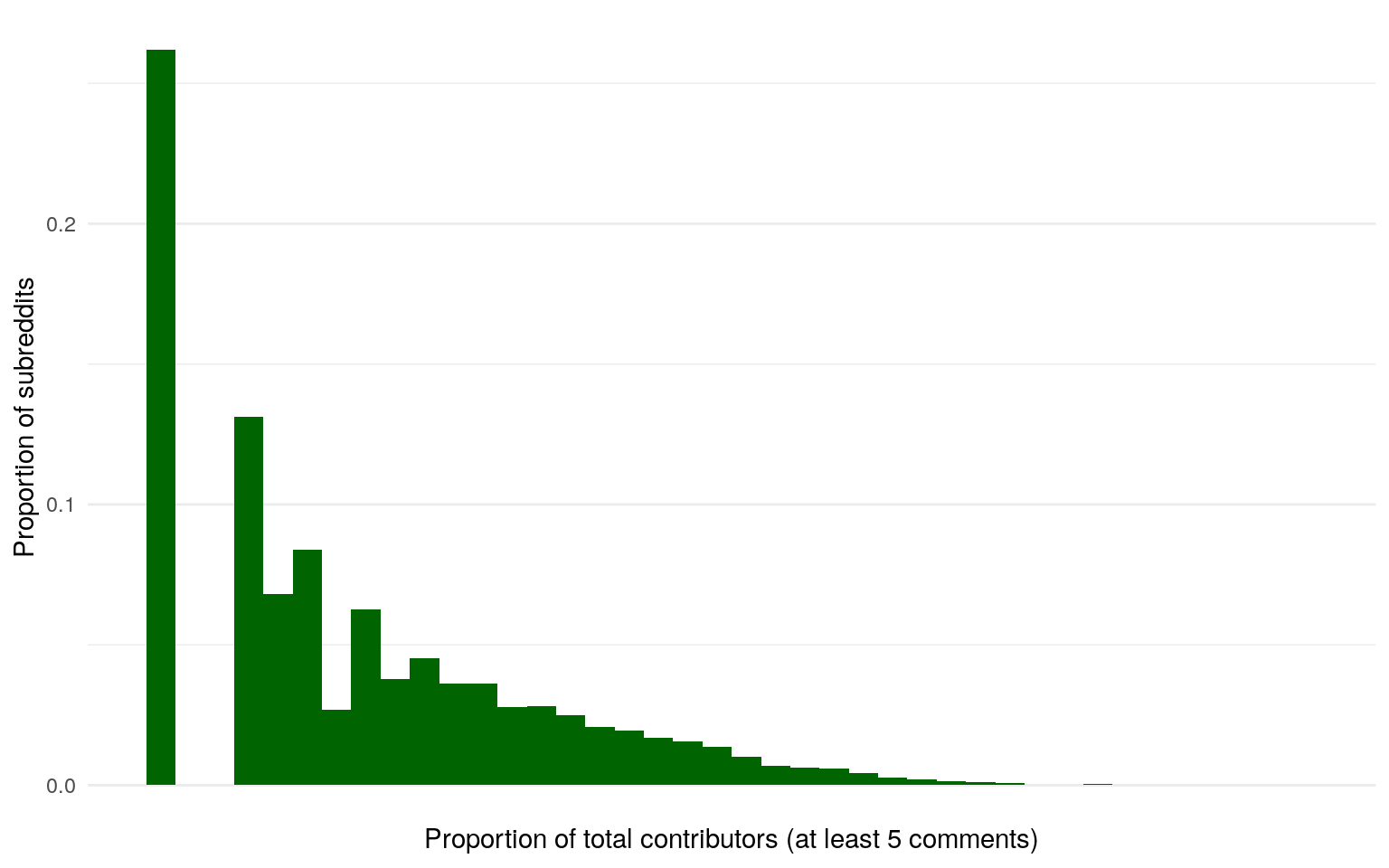
Data from Stuck_in_the_Matrix on BigQuery
The number of groups each user belongs to is also heavy-tailed
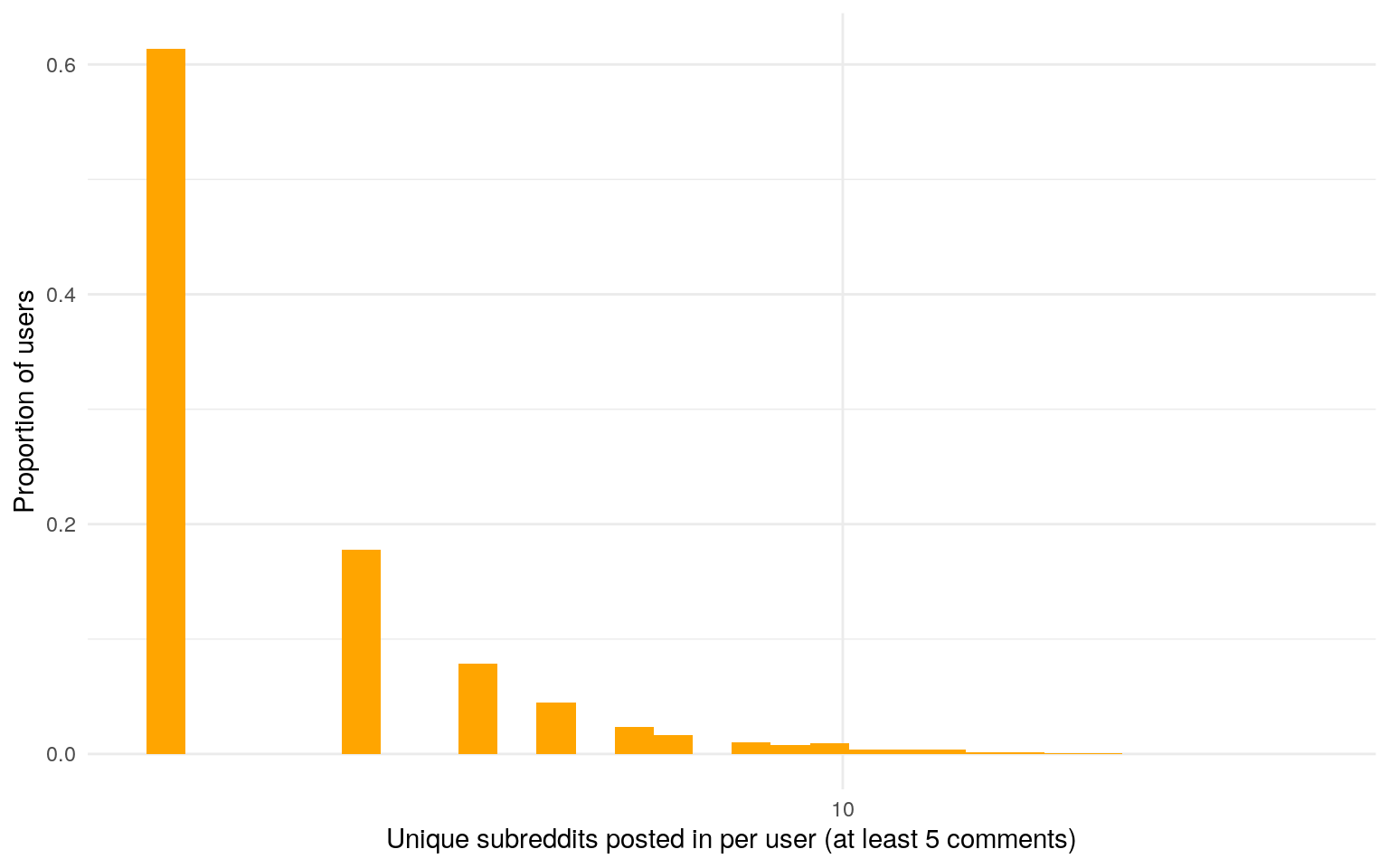
Data from Stuck_in_the_Matrix on BigQuery
Null model as baseline
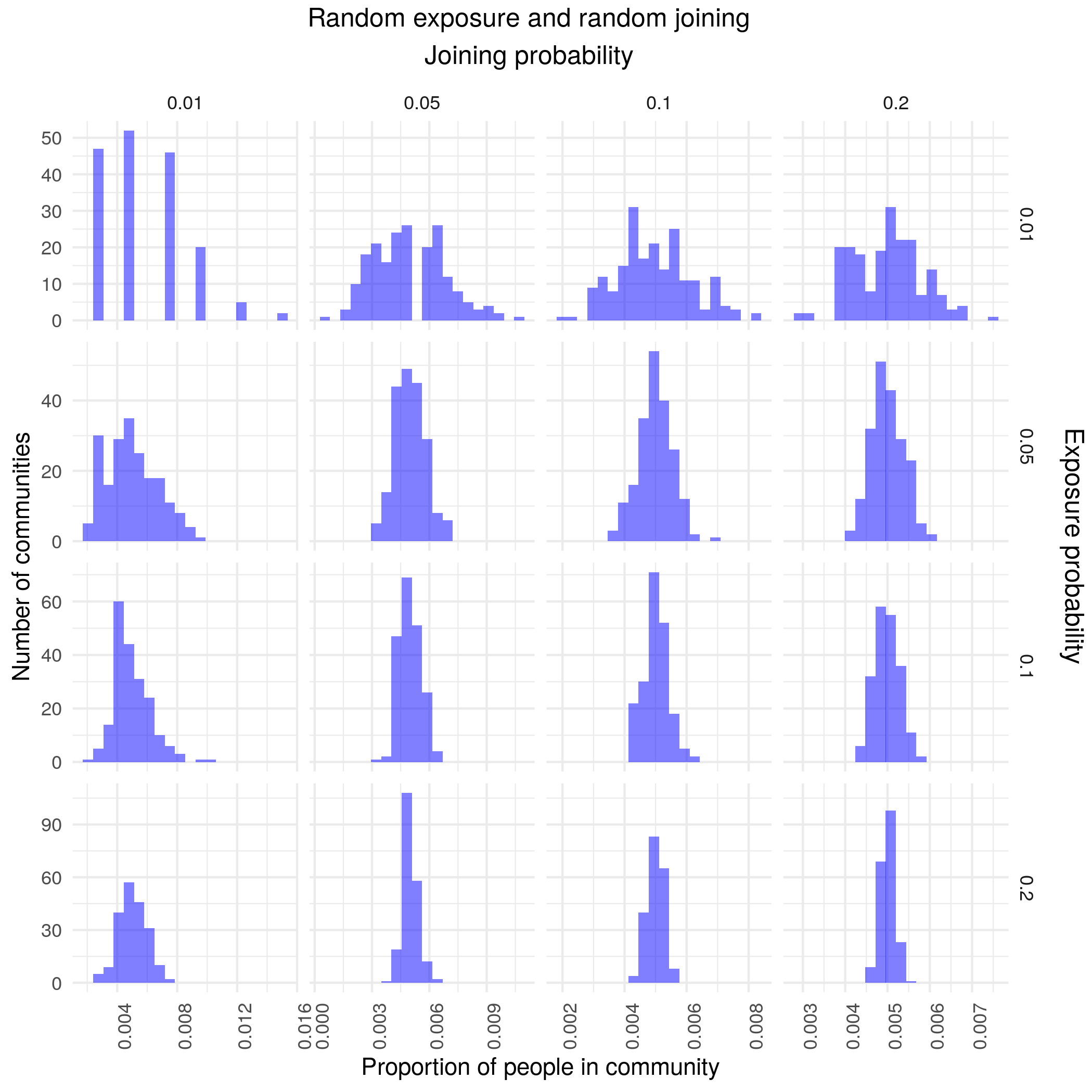
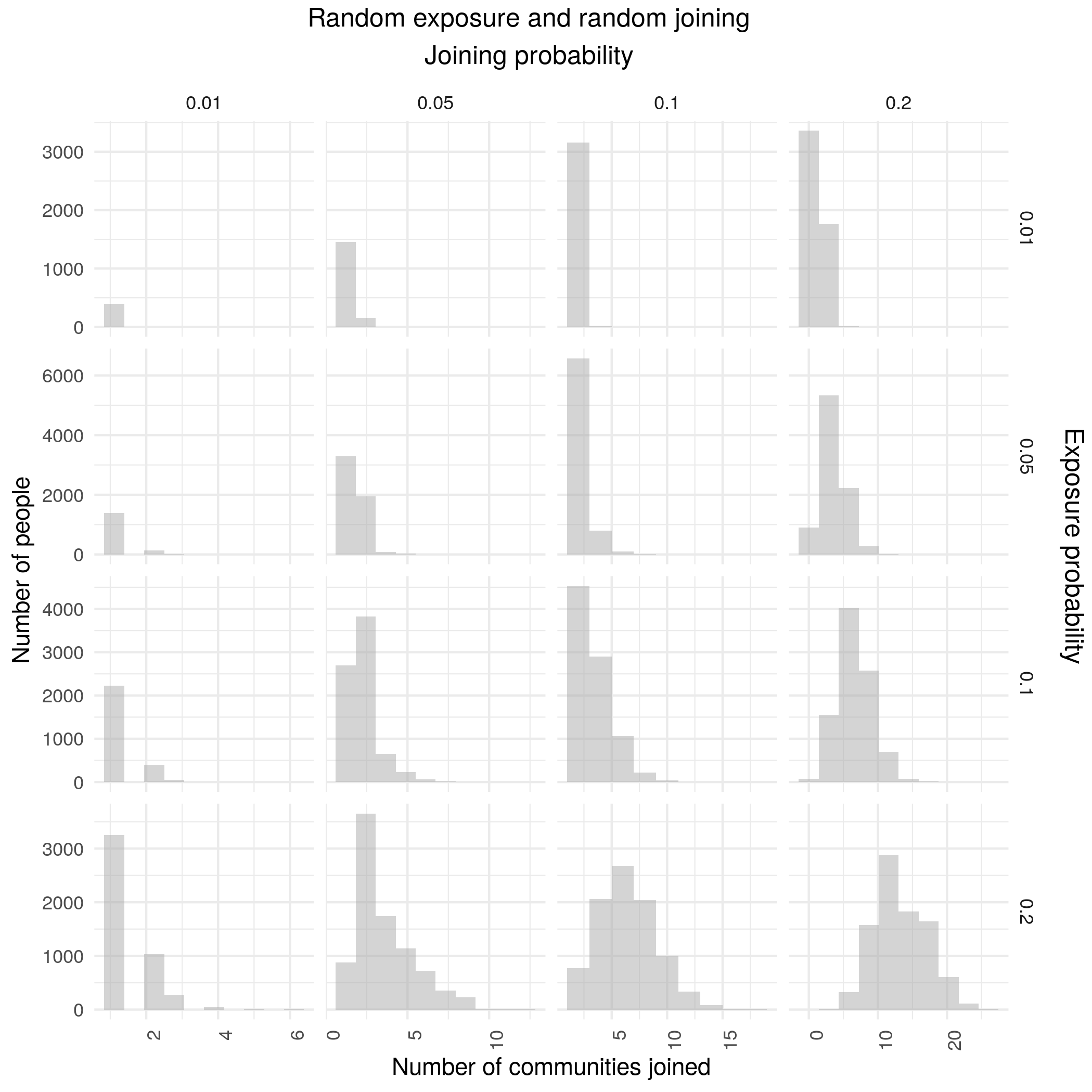
Expected utility models are skewed but not heavy-tailed
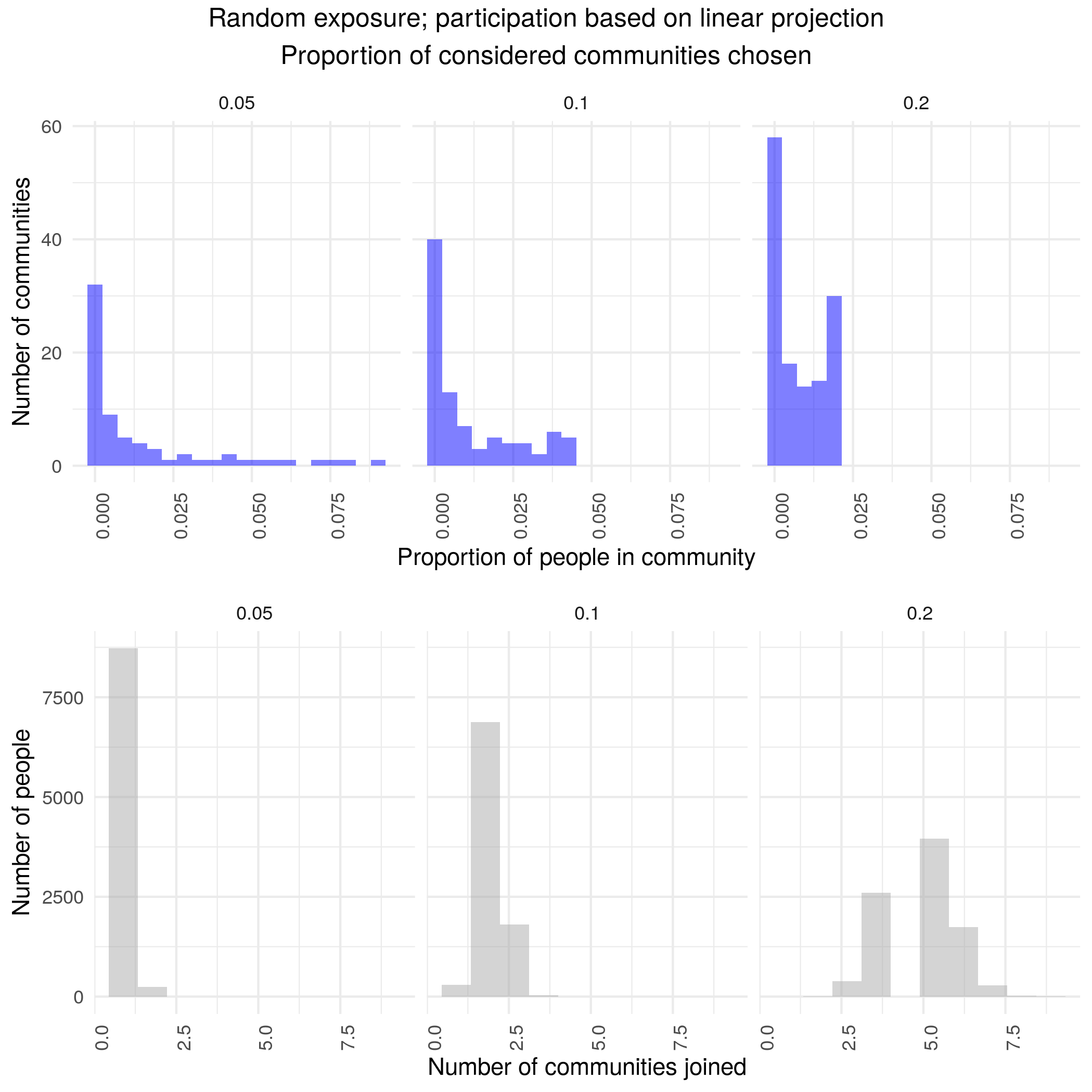
Naive versions of social exposure are not skewed
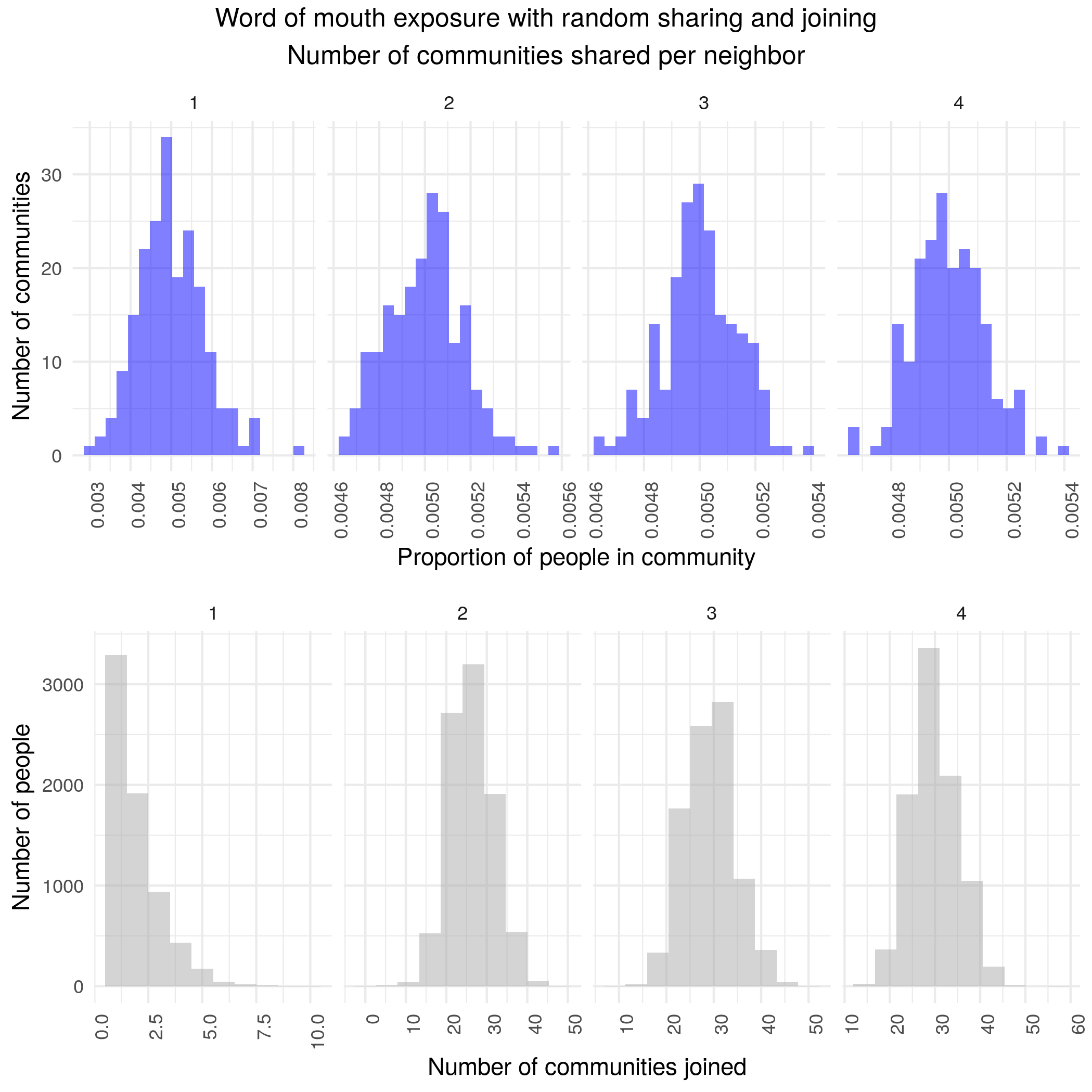
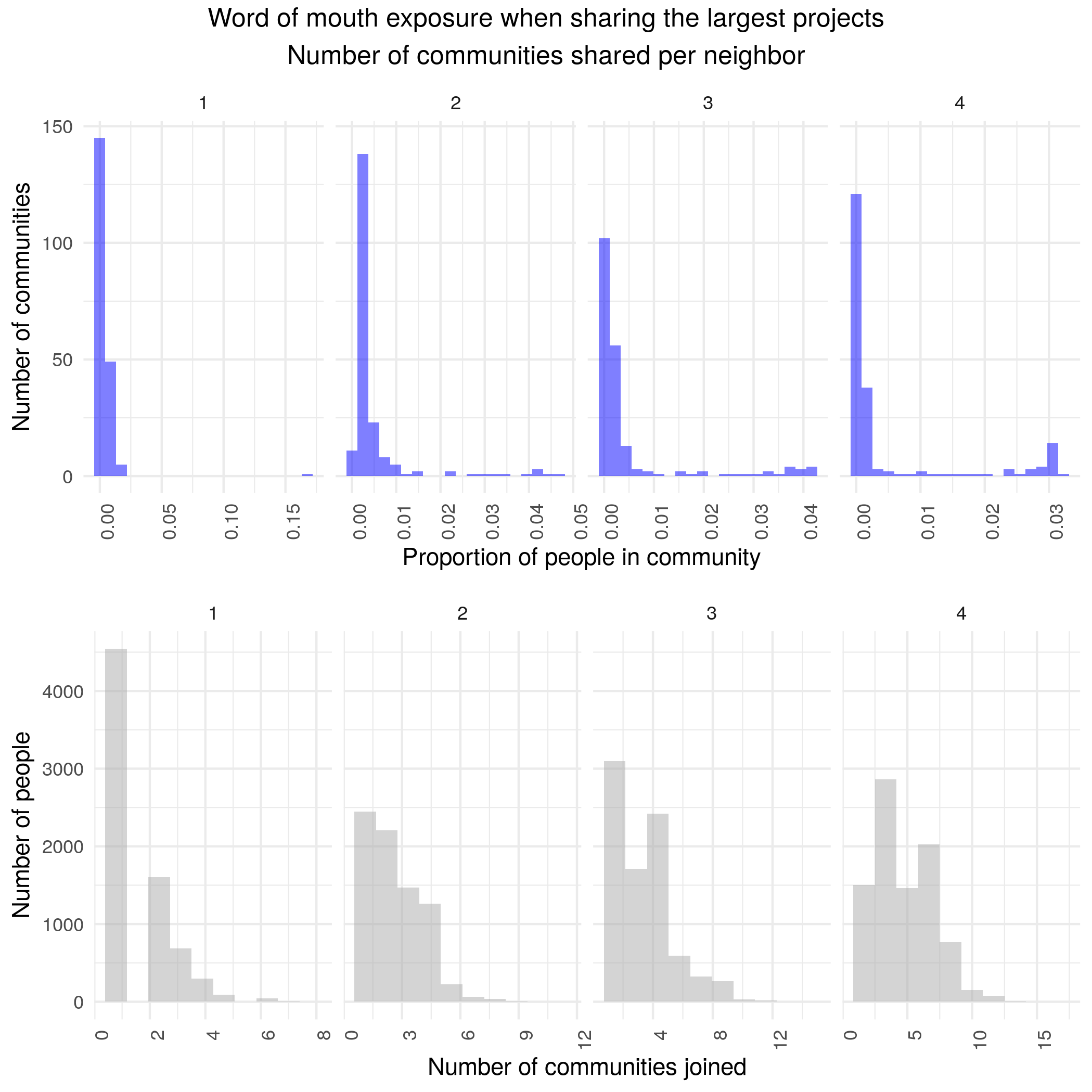
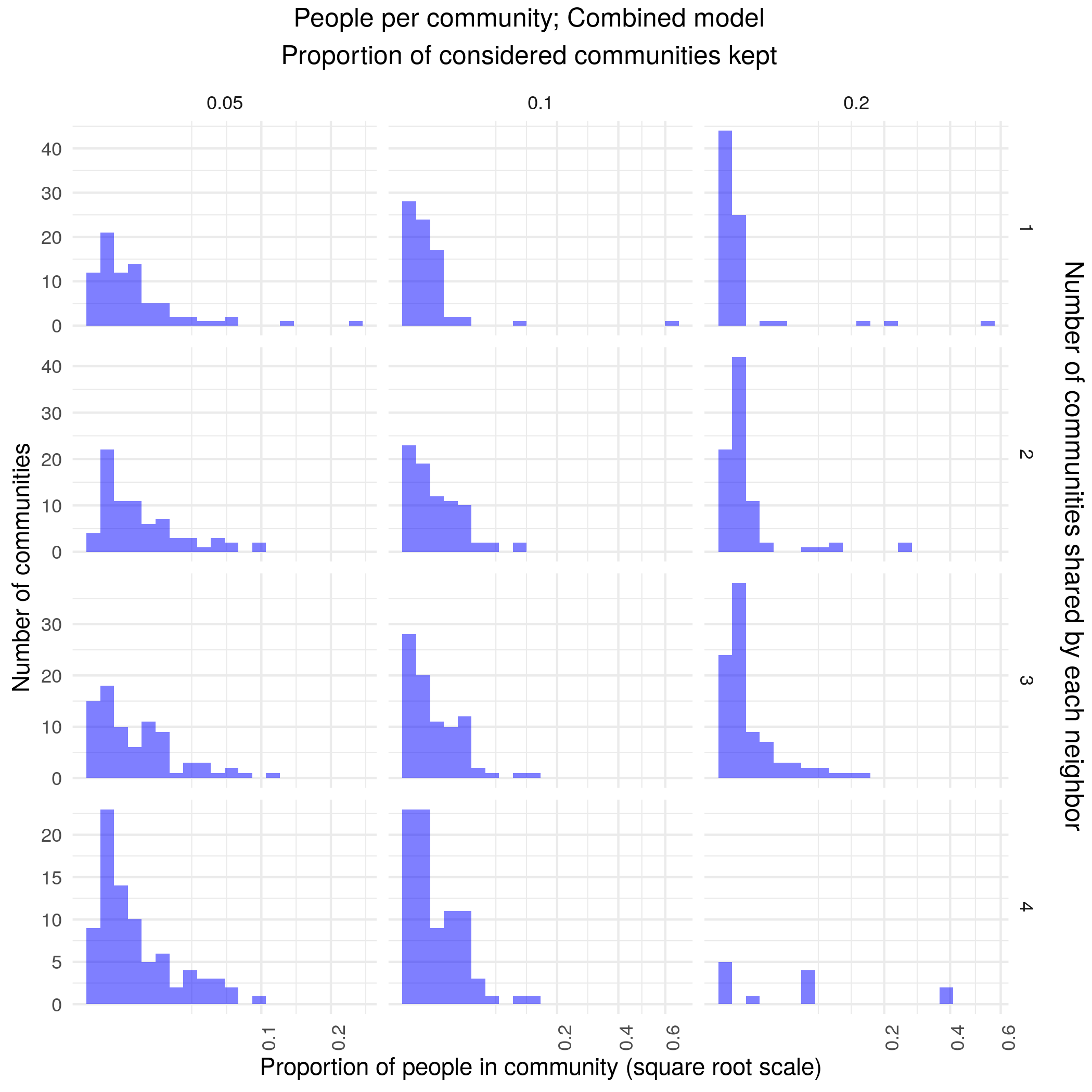
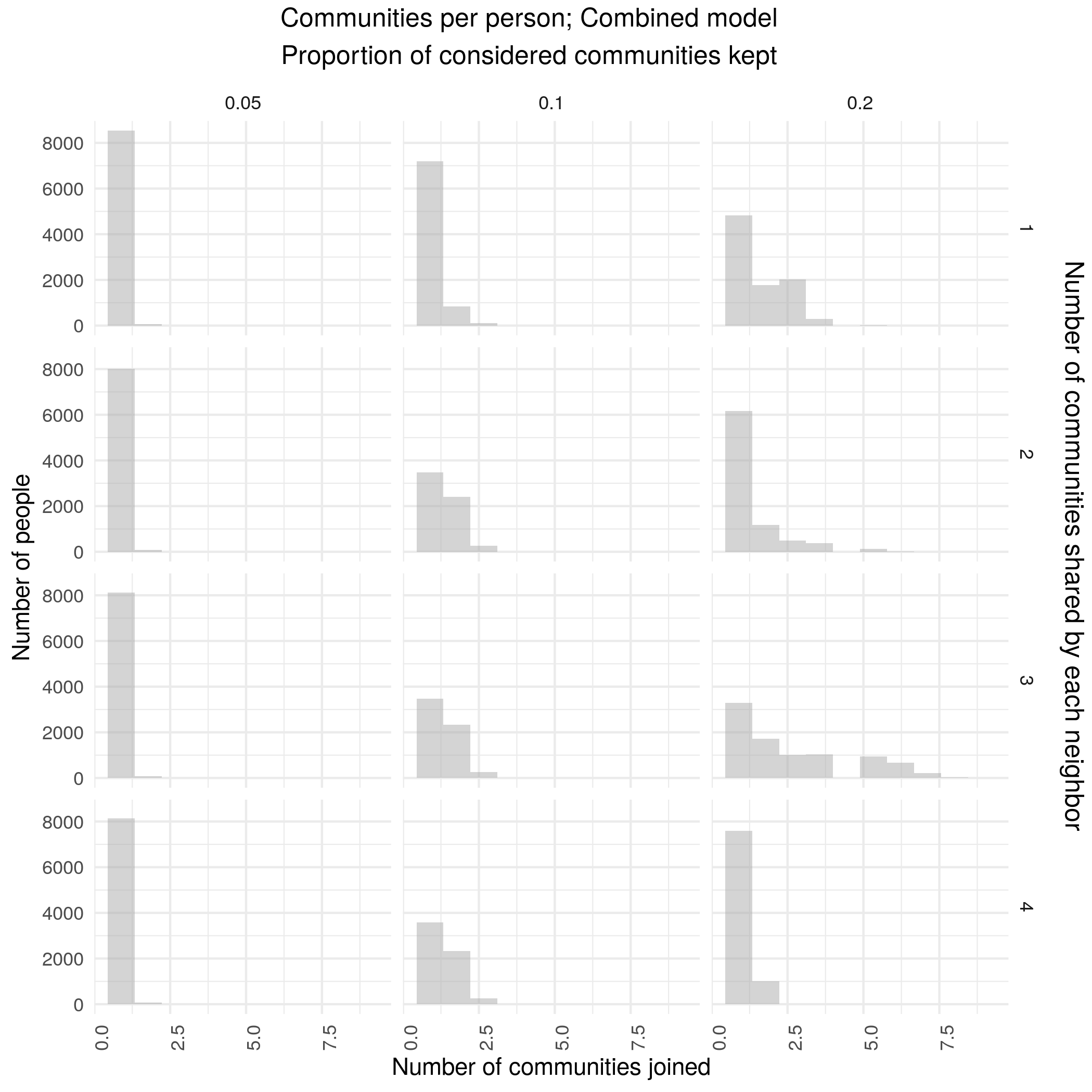
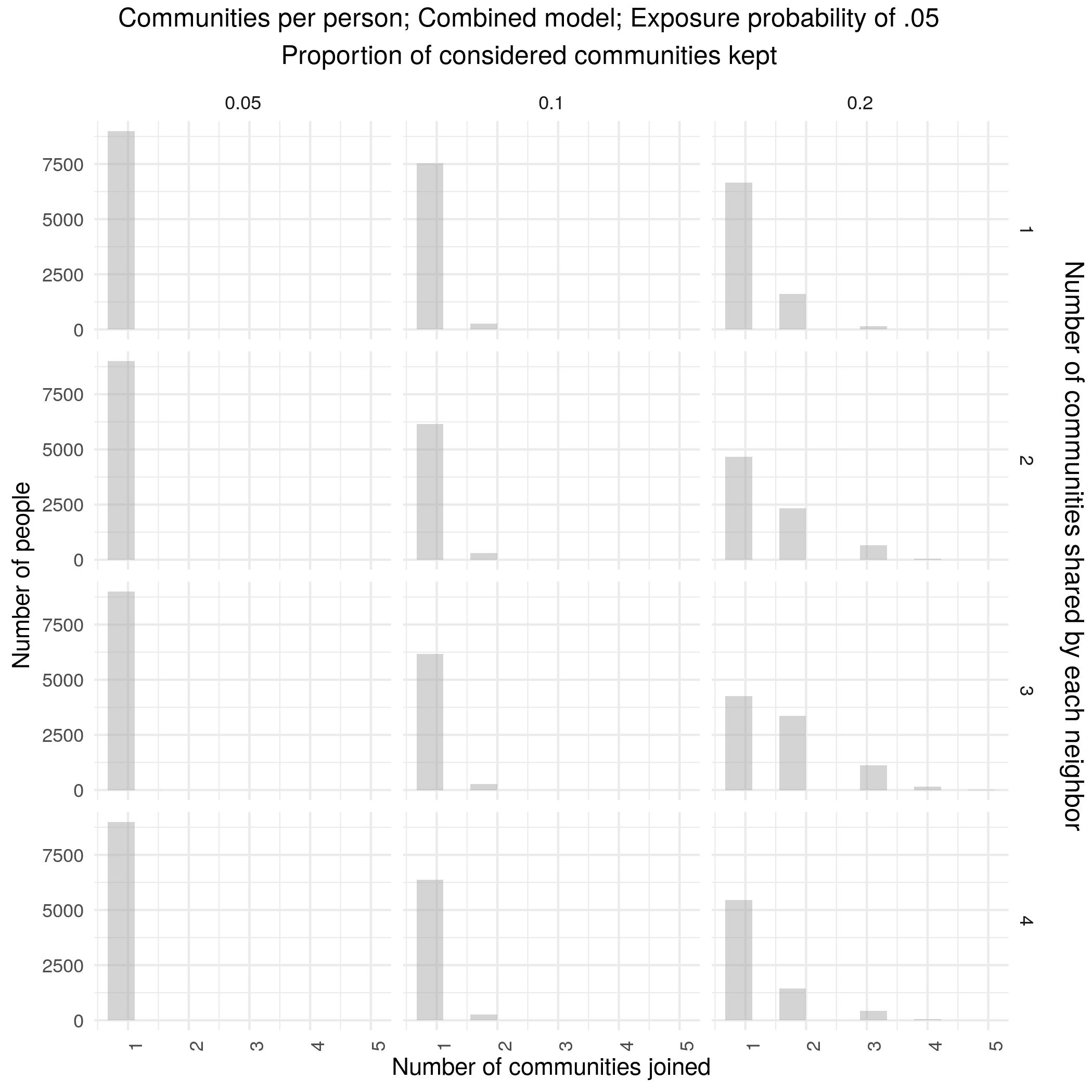
A combined version is robust with community sizes roughly similar to reddit
Productivity Model
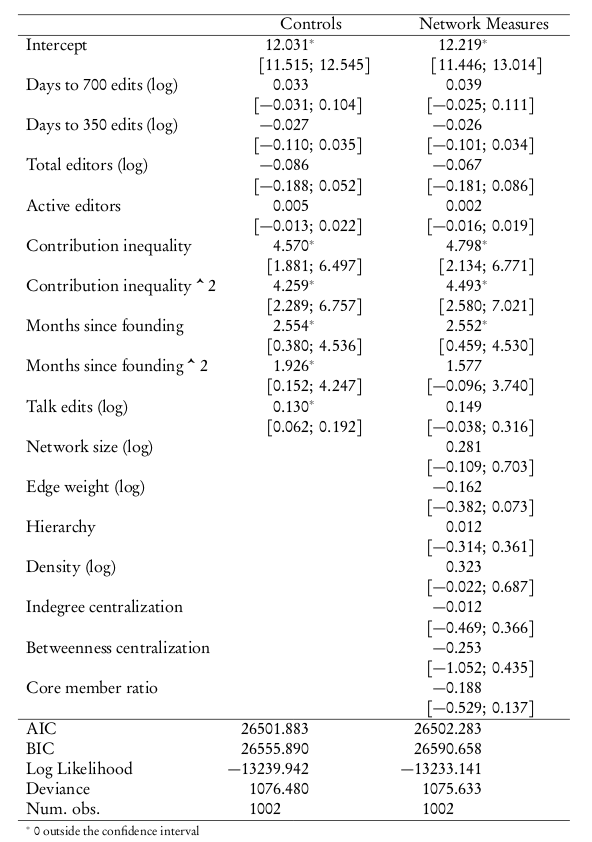
Survival Model

Robustness tests
Cutoff @ 500
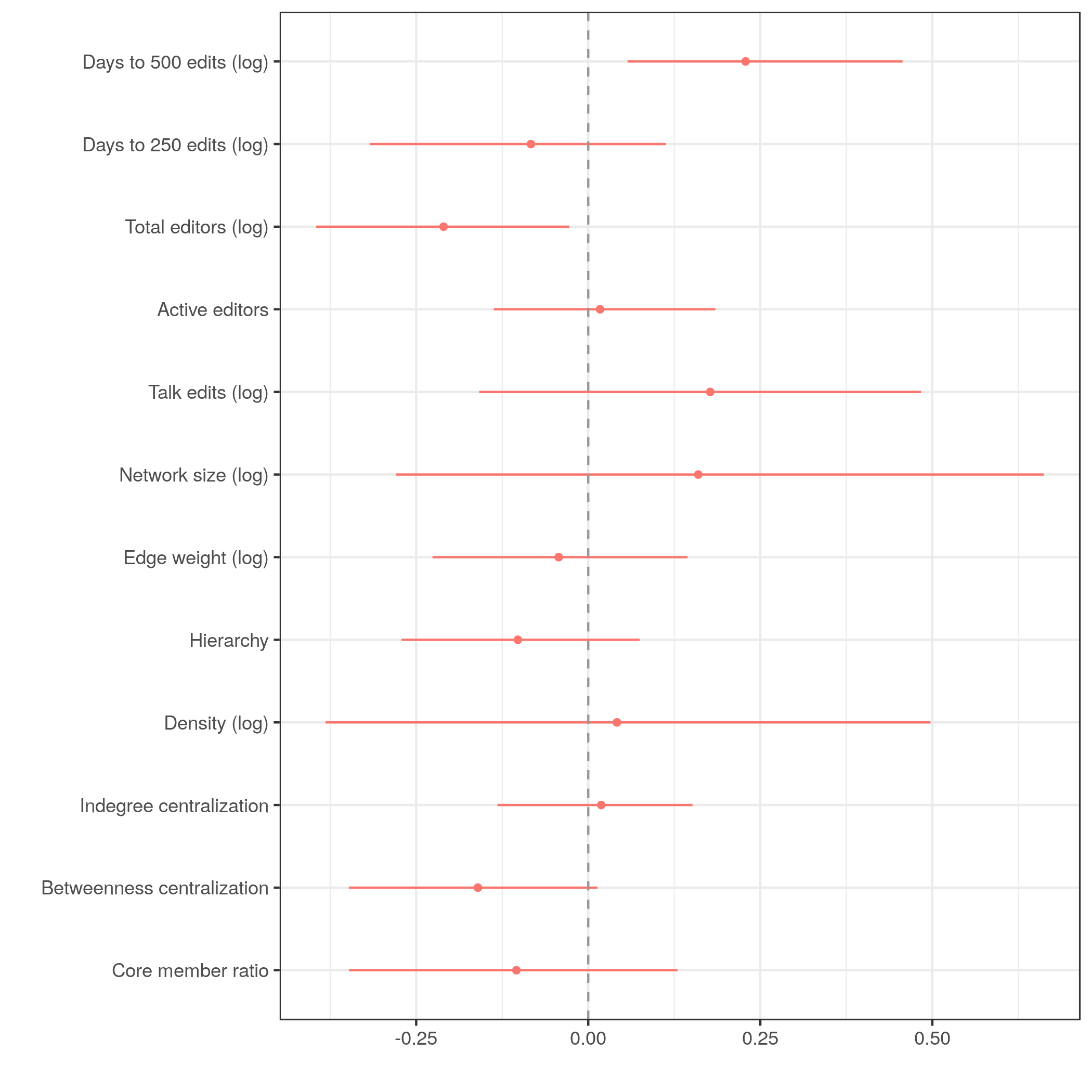
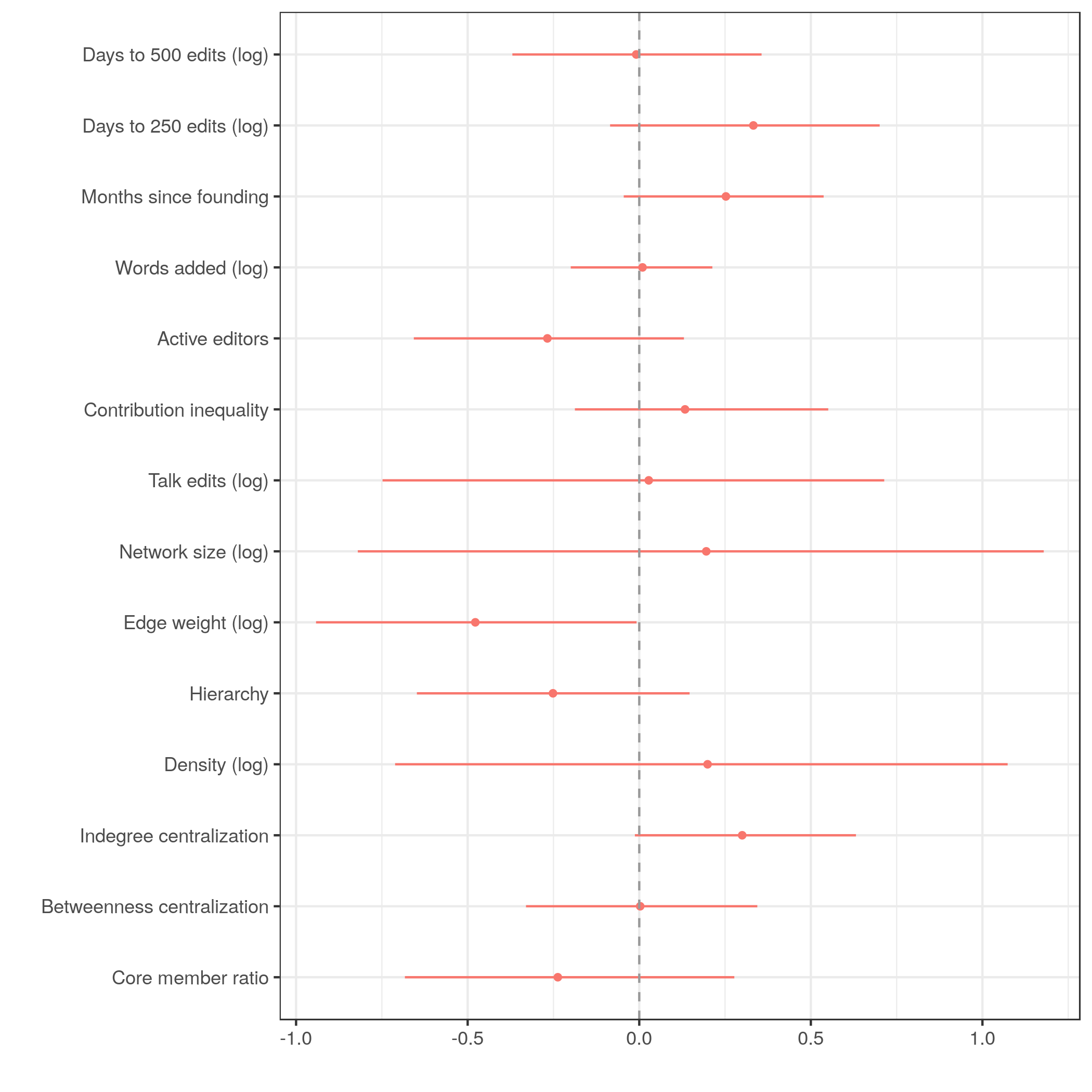
Robustness tests
Cutoff @ 900
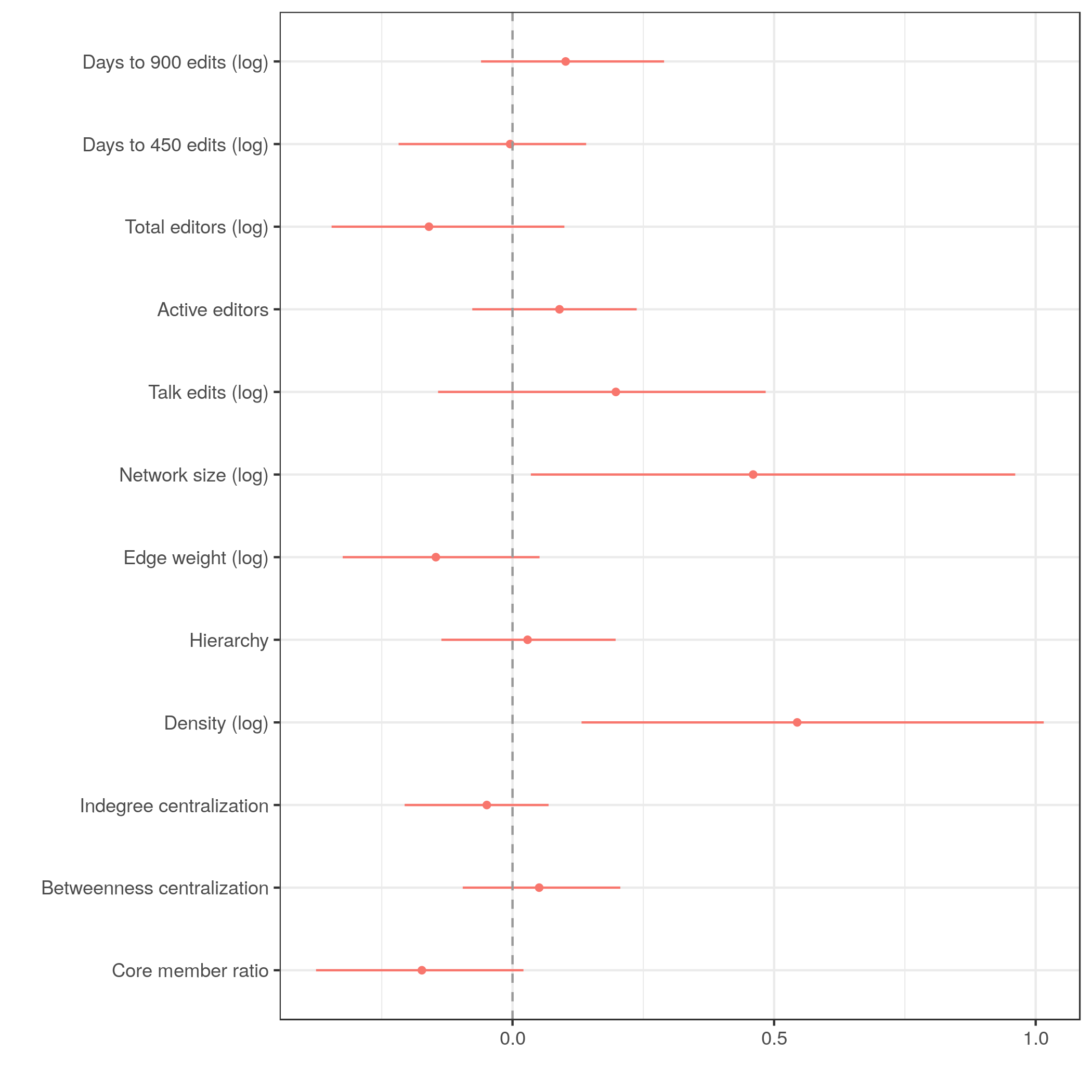
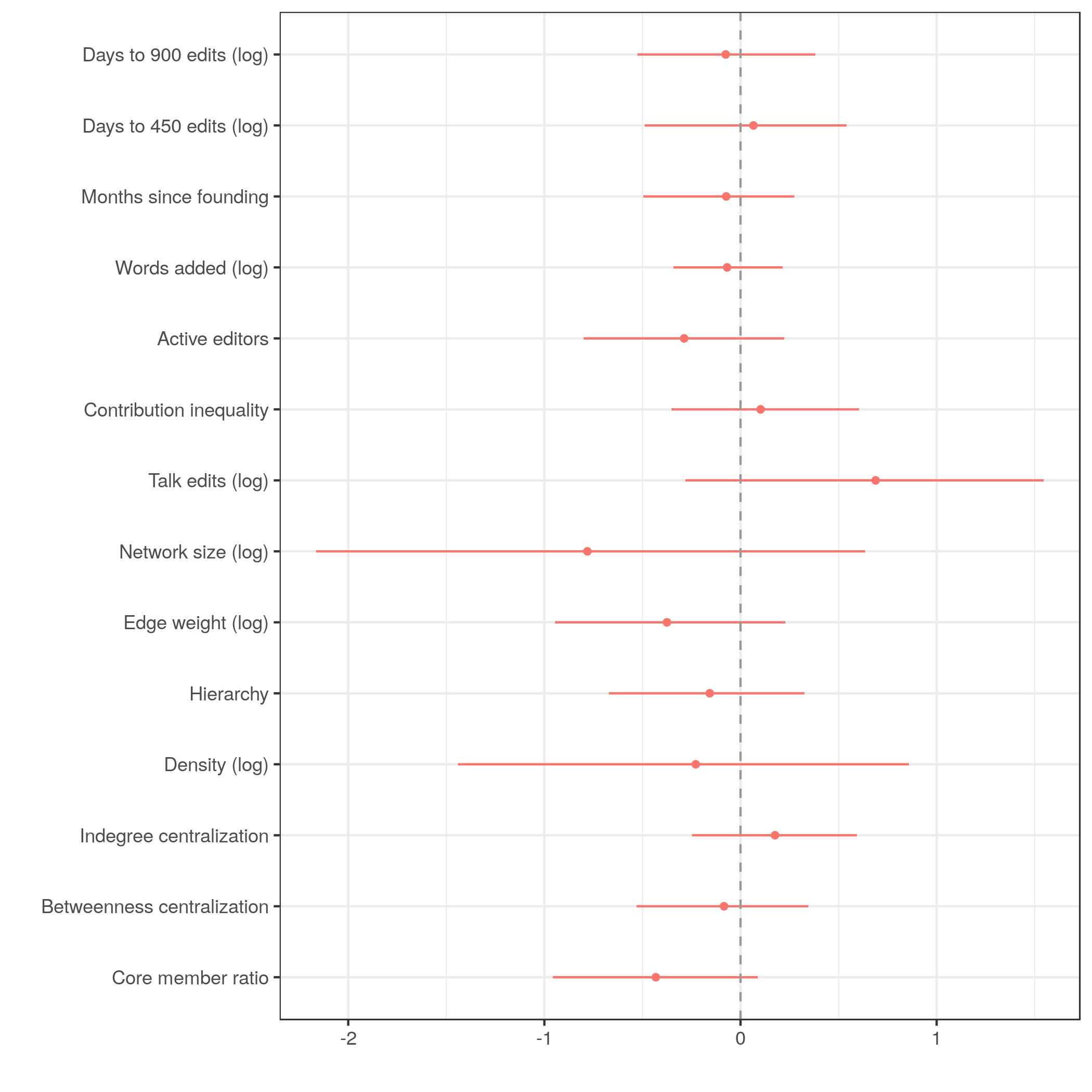
Robustness tests
Dichotomize edges @ 3
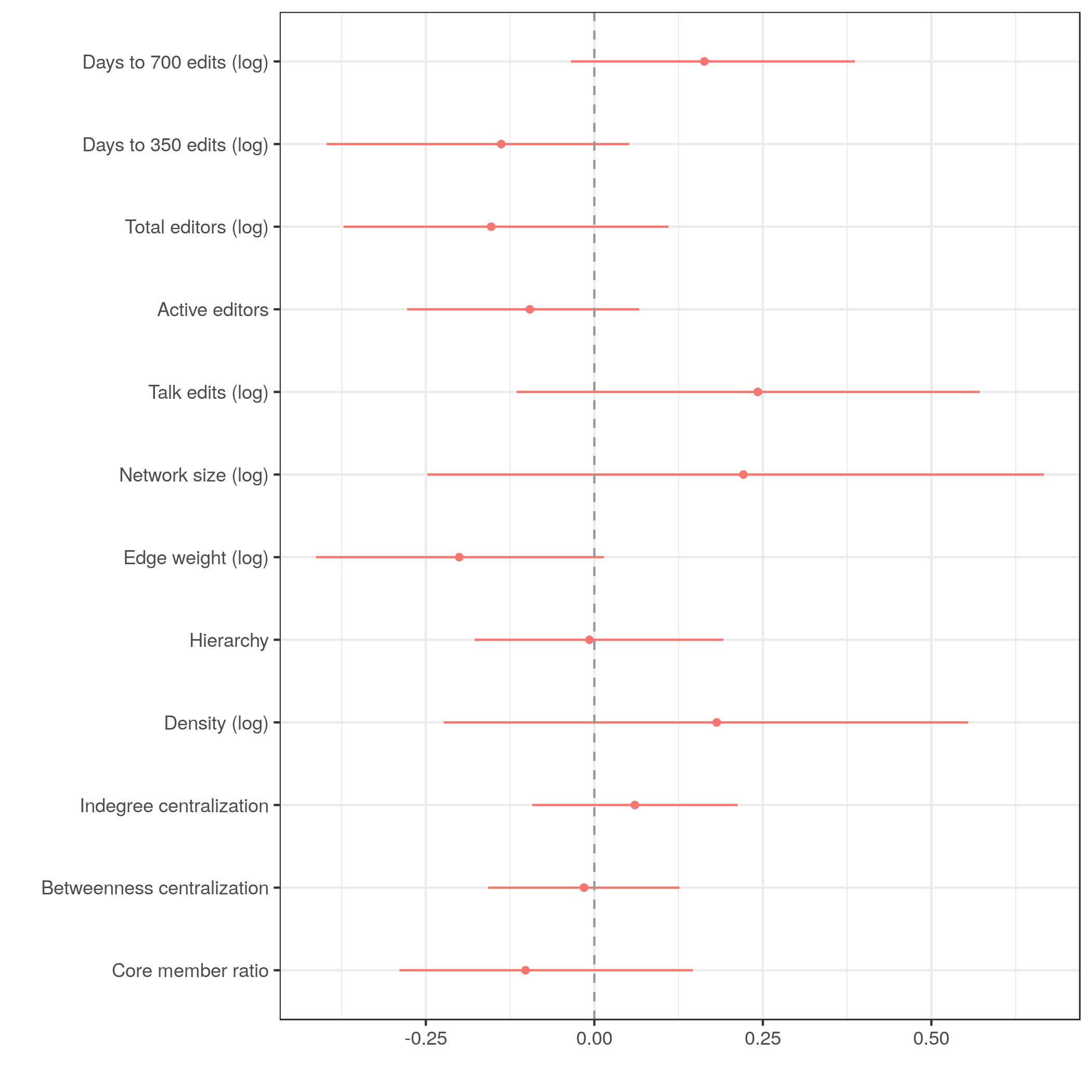
Coreness description

Degenerate graph example

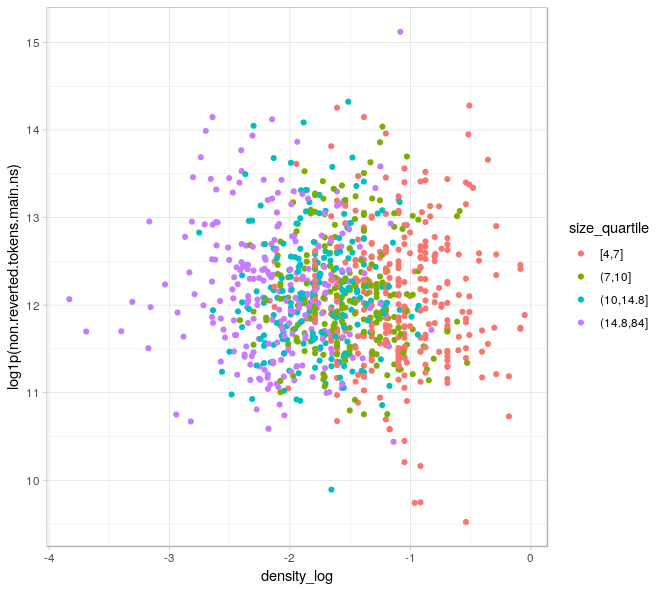
Density with size quartiles
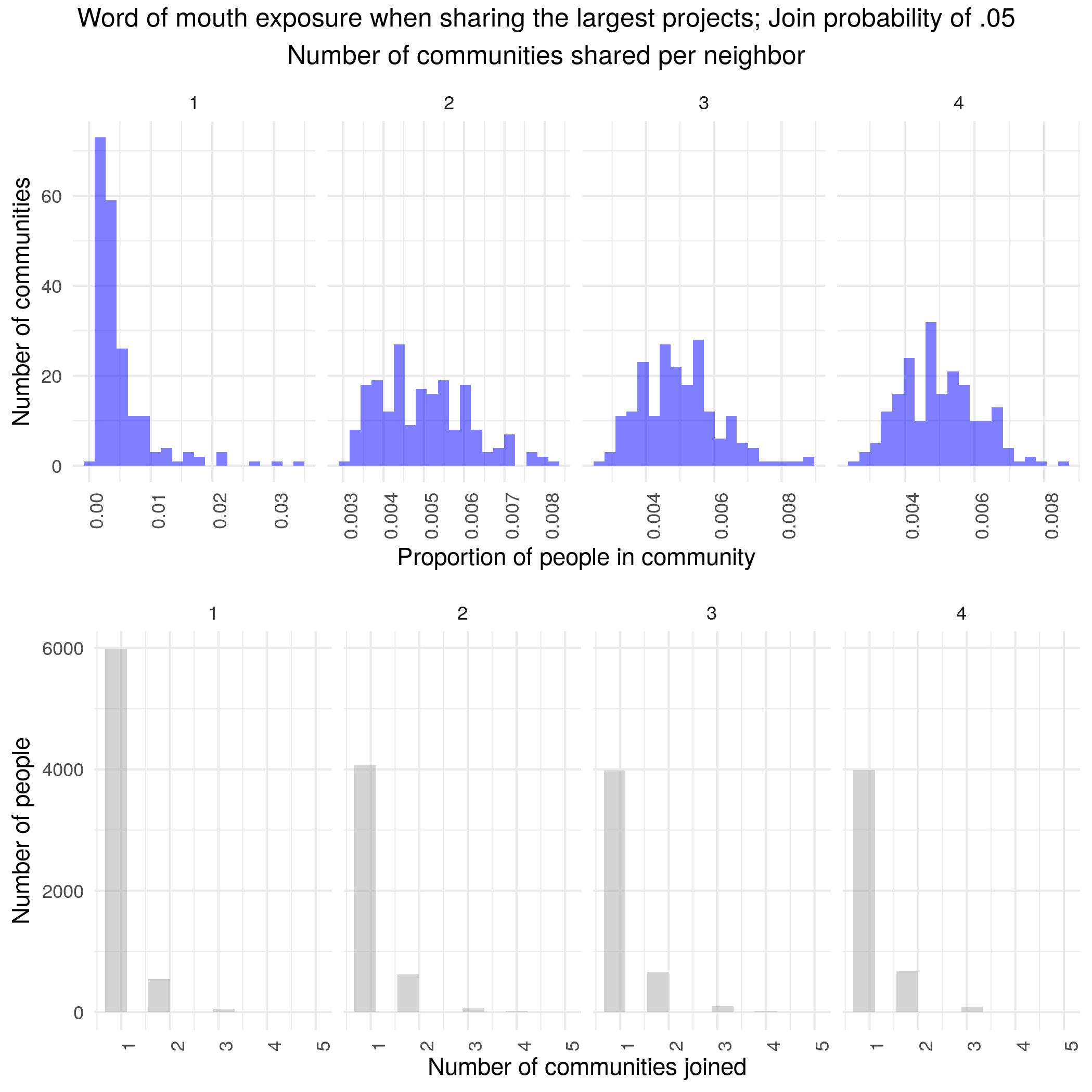
Word of mouth results are fragile
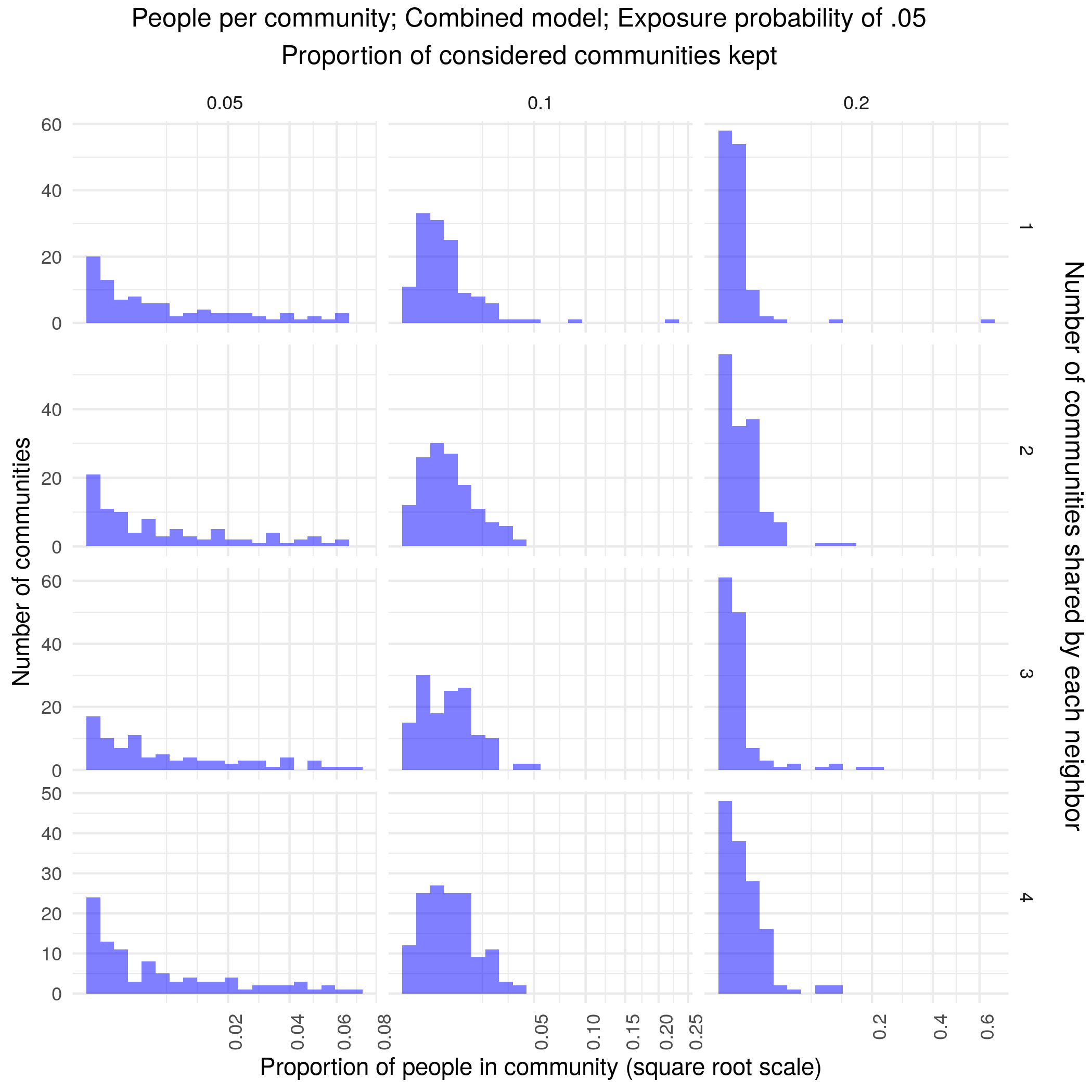
Combined models are much less fragile
Social exposure and participation processes in online communities