Using Social Media and Online Community Data for Social Science Research
Jeremy Foote
Brian Lamb School of Communication
Purdue University
Three main types of observational online data
- Web pages
- Social Media



- Online Communities



Project 1 - Google Maps and OpenStreetMap

“Zooming in” on the individual-level causes
- Big question is how competition influences an open source mapping project community
- It hurts it!
- Having digital data lets them ask why
- New members stop contributing but established members increase their dedication
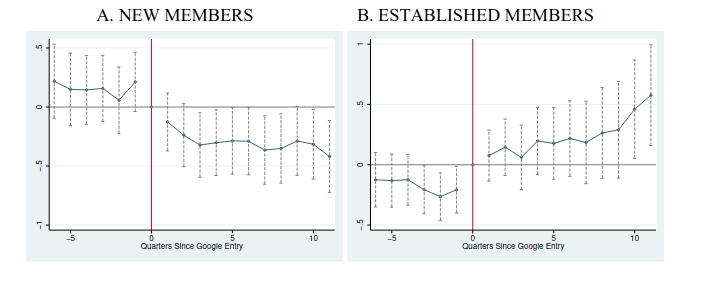
Figure 3 from Nagaraj and Piezunka, 2020
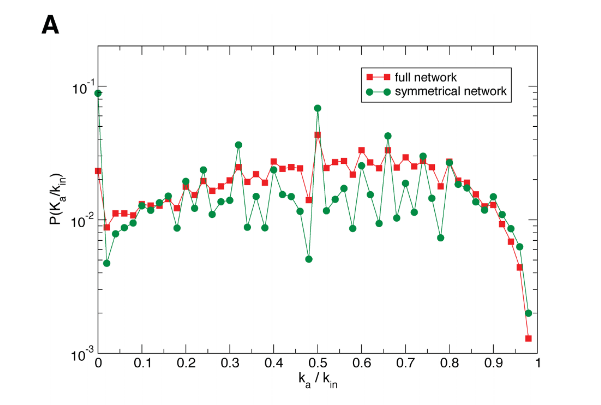
Project 2 - How do protests spread on Twitter?

How do people decide when to post a supportive hashtag?
- People have different thresholds before joining in (Granovetter, 1978).
- Gonzáles-Bailón et al. measured this threshold empirically
Project 3 - Wikipedia’s declining userbase
- Wikipedia study found a “rise and decline” pattern.
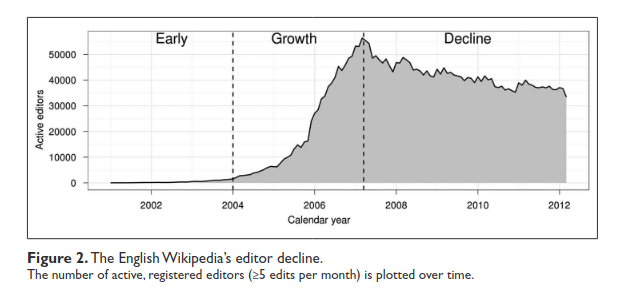
- Caused by Wikipedia’s quality control
Comparing many communities
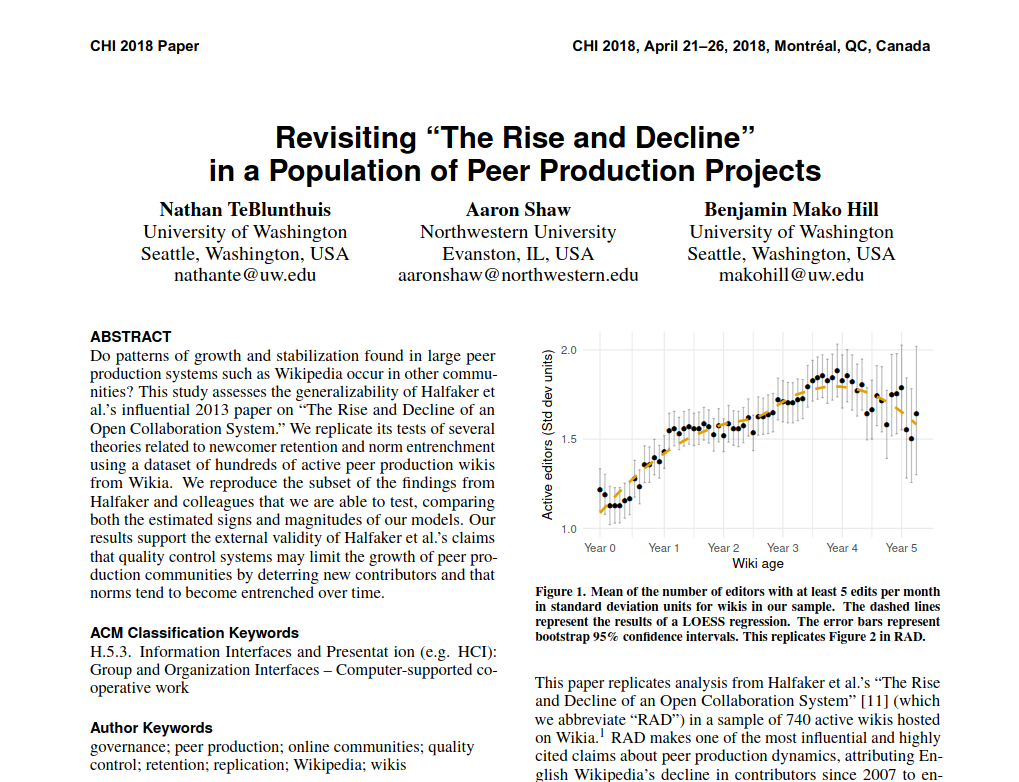
Looking at many communities helps to identify patterns
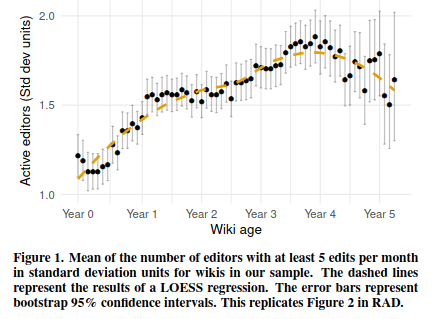
- TeBlunthuis et al. found that this patterns was common across lots of wikis of various topics and sizes
Project 4 - Combining computational and qualitative approaches

Further reading

Thanks!

Jeremy Foote
Brian Lamb School of Communication
Purdue University
@jdfoote